How to Train an LLM: Part 4
Welcome back to the continuation of Part 1, Part 2 and Part 3 of the saga.
In the last worklog, I settled on an architecture with a Llama-style base, QKNorm, MixAttention instead of standard GQA, and cross-document masking. If you want to learn more about that, check out the last section of this worklog.
Introduction
I have been quiet about the end use case I have in mind that justifies doing a pre-train. I have a specific architecture and strict criteria (blazing-fast, local inference with a decent context window) in mind, which limit my options for models I can simply post-train. Working across the whole pipeline has been fun, it takes a certain kind of persistence to debug through data, code and architecture for days on end.
My goal is to build a punch-packing code fill-in-the-middle (FIM) model. I am surprised at how we don't have a powerful, small, self-hostable FIM code model. Early versions of GitHub Copilot used 12B param code-cushman-001 by OpenAI, and we have come a long way since then; Copilot now relies on much larger GPT-5–class models.
It's going to be hard to compete with such a capable model. 4o was trained on multiple trillion tokens, neither do I have that scale of data nor do I have a giant wallet for that much compute.
Here are a few ideas I am NOT subscribed to:
- 1B params: I simply want to see how far I can get w ~1B and I might upgrade later (although I am dreading debugging FSDP).
- Type of model: Decoder-only, autoregressive models can only take me so far. Get the hint?
- "Compute > Data": After reading some papers, I believe I have a decent shot at this. To be clear, with a bunch of data and a ton of compute, you can get great models (current industry recipe). Being the underdog, I'll have to map my moves to preserve compute cost, which means each byte of data I train on should have maxxed-out signal a.k.a. I might have to farm some tokens and dive down the permissively-licensed GitHub code depths... but it's ok if my efforts might bring something awesome to the community.
- Pre-training: I actually only care about end model quality. Pre-training from scratch vs post-training an existing model are both options I will explore as needed.
In this blog, I want to talk about data and my first FIM model pre-train, which I trained for 5B tokens (undertrained). I originally wanted this post to be about the “final” model, but I do not think I have the right recipe just yet. I need to spend some more time with my codebase.
Data for FIM
I spent a long time understanding what kind of data FIM models currently consume. I have read through papers on Deepseek-Coder, Structured FIM, SmolLM2, StarCoder, OpenAI's OG FIM, and many others.
From all this, I have a few key insights:
Less is More
Some data-focused papers emphasize filtering the dataset and training on the smaller dataset while still performing better on evals. I will speak on evals more later. This idea of "Cognitive Core" is appealing to me where the model is trained to understand the essence of a language or a design pattern at train time and performs well at test-time given additional information in-context.
Datamix
For code FIM, I train on 90% code and 10% English data. Let's talk about what both are composed of:
- Code: My initial plan was to source datasets by scraping GitHub. I think that is not the most productive use of time given numerous other organizations / projects like BigCode have done the leg work. While I would like to mix and match different datasets (synthetic + real), for my MVP model, I opted to train on SwallowCode which is a filtered + synthetic code dataset.
- English: If code consists of thorough comments, my intuition is the model can learn the necessary relationships behind code tokens. However, OpenAI's paper added 10% code-adjacent English, therefore, my plan is to use Stack Overflow Q&A pairs, arXiv abstracts and other sources of technical English into the mix. The whole point of adding English to the mix is so the model's outputs can be pseudo-conditioned using English prompts as comments (GitHub copilot's flow).
Data format
FIM-style cloze objectives are conceptually similar to what BERT-style masked language models excel at. However, OpenAI's FIM paper describes the FIM-for-free property of modern decoder-only LMs. Let's say I have the following snippet of code in my training data:
def calculate_sum(numbers):
total = 0
for num in numbers:
total += num
return total
result = calculate_sum([1, 2, 3, 4, 5])
print(f"The sum is: {result}")
If we want to feed these tokens to train our FIM model, we restructure the input to roughly look like the following:
<|fim_prefix|>def calculate_sum(numbers):
total = 0
for num in numbers:
<|fim_suffix|>
return total
result = calculate_sum([1, 2, 3, 4, 5])
print(f"The sum is: {result}")
<|fim_middle|>total += num
Simply put, code before middle (or prefix) comes first, then comes code after the middle (or suffix), and finally, we let the model see what should come in the middle. The sentinel or special tokens (e.g. <|fim_prefix|>) add structural signal to the model during training. The format above is PSM (or Prefix-Suffix-Middle), there is another format SPM (or Suffix-Prefix-Middle) which allows for better KV-caching.
OpenAI's FIM paper as well as the Structured FIM paper linked above are where I draw my inspiration from. Let me break these ideas down & how I use them.
- The Deepseek Coder paper experiments with formatting code, as shown above, versus L2R (left-to-right, which is the vanilla format) and found that a FIM rate (or percentage code that is FIM formatted) of 50% is optimal for FIM generation while preserving L2R generation. I use 75% as our FIM rate.
- SPM + PSM: I train on 50% SPM and 50% PSM data. According to my intuition, training on both formats make the model actually understand code structure and positional encodings within code. During inference, I will go for SPM for it's KV cacheability.
- Structured FIM proposes that masking random positions of code to be the
<|fim_middle|>tokens is sub-optimal and instead, masking AST-boundary-aware produces stronger models. Before this paper, most FIM models likely trained on randomly selected masks. Intuitively, this makes sense as the model gets to understand underlying structure better throughout training. I use 90% AST-aware and 10% random masking. Why 10% random masking? The data you train models on are supposed to be representative of end-use, and plenty of times I need the model to fill in starting halfway through a variable name, etc.
Determining how long the mask is a challenge by itself. My first idea to support a range of mask sizes (similar to IRL coding flow) was to make mask_length = clamp(normal_distribution(mean=50, stddev=40), 1, 100). The model I ended up pre-training calculates mask length with that and it's... sub-optimal in hindsight. My thinking was - I'd want the model to complete full AST trees worth of code, so 40-60 tokens should be good for the average generation - but this absolutely messed up shorter, more common generations, with the model not knowing when to stop. Therefore my new updated formula is mask_length = uniform_distribution(a=1, b=100) which should provide better generations across a wider range of use cases.
Eval setup
For simplicity's sake, I created my own eval. To make it realistic and simple, I'll take 10 in-production files from my own training codebase and, with minimal edits, manually select masks of different sizes and subtrees such as if statements.
This guarantees the model has definitely neither seen these exact masked snippets nor the code itself during training.
Edited example (... is code removed for brevity):
<|fim_prefix|>
...
self.weights.append(dataset_config.mix_ratio)
self.buffer: <|fim_suffix|> = []
self.doc_ids = []
self.current_doc_id = 0
...
<|fim_middle|>List[int]
The example above tests if the model understand types in python.
My First FIM Model
I decided to put all the theory to rest and train a model. I relaxed some constraints to get a baseline: I only use random FIM (no AST-based masks), python-only code part of the datamix (10% english still kept in the mix) and the 0.6B model is llama-arch + QK norm + cross-doc masking (no mixattention yet). I spun up 2xH100s to make this happen and trained over 5B tokens instead of 20B (definitely undertrained).
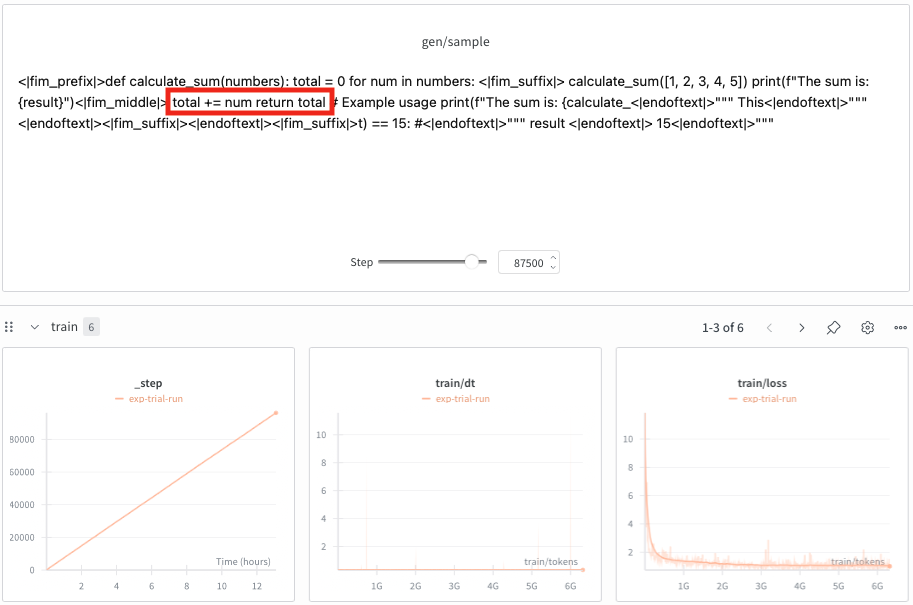
The gen/sample generations are supposed to help me vibe check the model's outputs. The generation is correct, but it doesn't add the <|endoftext|> token until a few tokens later. I think this is because it sees so few examples that output only a few tokens, so the model thinks it has to generate a few more tokens. I could be wrong, and this behaviour could totally be an artifact of undertraining. Suffice to say, this model does horrible on my evals.
Conclusion
This has been my shortest worklog in a while. It feels like not much got done, but in fact, a lot was done. I gained invaluable intuition on data massaging, have evidence that my model/dataset combination can work, and improved my training codebase, among other things!
Hopefully, I have good news in my next worklog :)
Omkaar Kamath