How to Train an LLM: Part 3
Welcome back to the continuation of Part 1 & Part 2 of the saga.
We left things on an abrupt note last time. After 3 days of desperate refactoring and debugging, we have solved the "loss going to 0.04" bug.
If you want to learn more about that, check out the last section of this worklog.
Introduction
If you haven't read the first two parts of this series, I am building towards a narrow-domain, 1B language model. Treat this as a storybook / worklog rather than a tutorial, I simply share my thought process, what worked FOR ME and my mistakes throughout the blog.
The end goal is fast, local inference while supporting decently long context inference. My plans are ambitious and I need all pieces of this puzzle to be in place first, therefore, I am focusing on a simple MVP for now.
I promise to be as scientific as I can for a non-paper. Anywho, this will be a long & fun read because I have a roster of things to run through like Cross-Doc Masking, Multi-Token Prediction, Muon, Proxy-model LR tuning, Multi-Latent Attention, MixAttention AND MORE!
Modded-NanoGPT is an awesome project with many experts innovating to make training runs faster on a low six-figure param model. Armed with a few ideas, my plan is to use a small proxy model to test my ideas.
To sum it up, I will be training a proxy 0.69B model (incl. embedding params) till we train on over 1B tokens. I will experiment by isolating ideas first (separation of concerns) on smaller models, picking successful ones and implementing all of them on the bigger 1B run. The main metric for comparison is Validation loss vs Tokens Trained, which allows for time- and batch-token- invariance!
The following image is my training baseline. Llama3 0.69B arch, 1B train tokens ([32, 128] batch size), Val loss: 3.38. Basically, mostly standard with a few changes to run better.

I don't know the best way to organize my ideas, so I will go with the high-level "Training Recipes" & "Architectural Study" headings.
Training Recipes
Proxy-model LR tuning
Simply put, this is testing different learning rates on a smaller "proxy" model and using simple heuristics to calculate the actual model's LR. I think it's a moot point at this stage given we have a whole swath of experiments left. It does make sense once I have a concrete idea of the end architecture. However, I wanted to leave this to foreshadow my next post's content.
Cross Document Masking
In most datasets, each row of data has texts of different lengths. Traditionally, when feeding these rows into LLMs, they padded rows with PAD tokens upto the preset seq len.
Nowadays, instead of padding, we collate each document (or row of text) till target seq len and a special token like <|end_of_text|> is used as a delimiter between documents. However, this causes a problem where tokens from different documents are attending to each other. Imagine tokens from a rap culture webpage is attending to tokens from financial news, no bueno.
Therefore, instead of simply applying a causal mask in attention, we also apply the cross document mask. Pytorch's FlexAttention API makes this SOOO simple!
This is only causal mask vs causal mask + document mask:
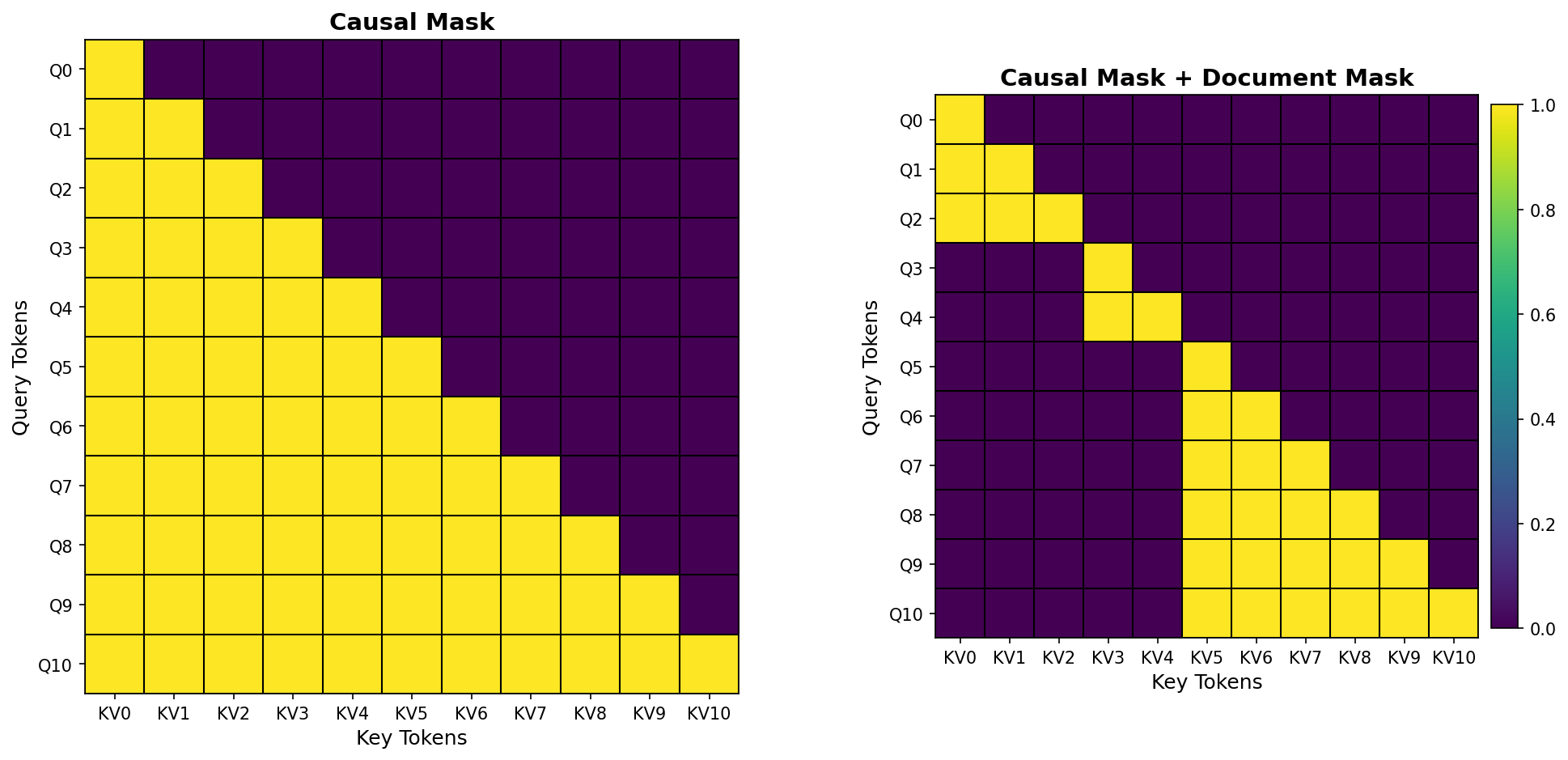
I won't bore you with implementation deets, but I had to make changes to my dataloader to return a document id per token as well as implement flex_attention correctly which was fun.
These were the results:
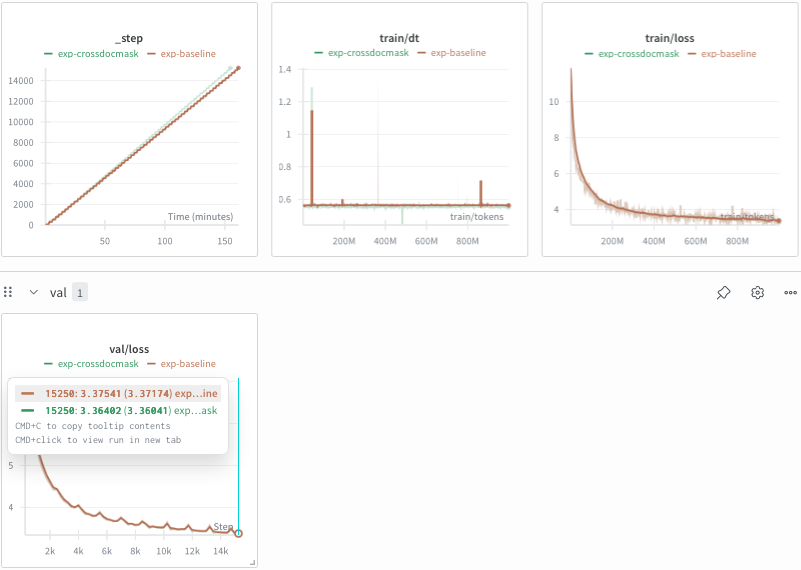
It is slightly faster, given the added sparsity in attention, and is on-par with the baseline (maybe even slightly better).
Muon
I won't go deep into Muon and why it's a good optimizer since I myself am coming to grips with the intuition, however, checkout Keller's blog to learn more.
Pytorch recently brought Muon into its API, so my job is easier. Following Karpathy's Nanochat, I used AdamW on embedding and norms (non-matrix params) and Muon on all matrix params (nn.Linear).
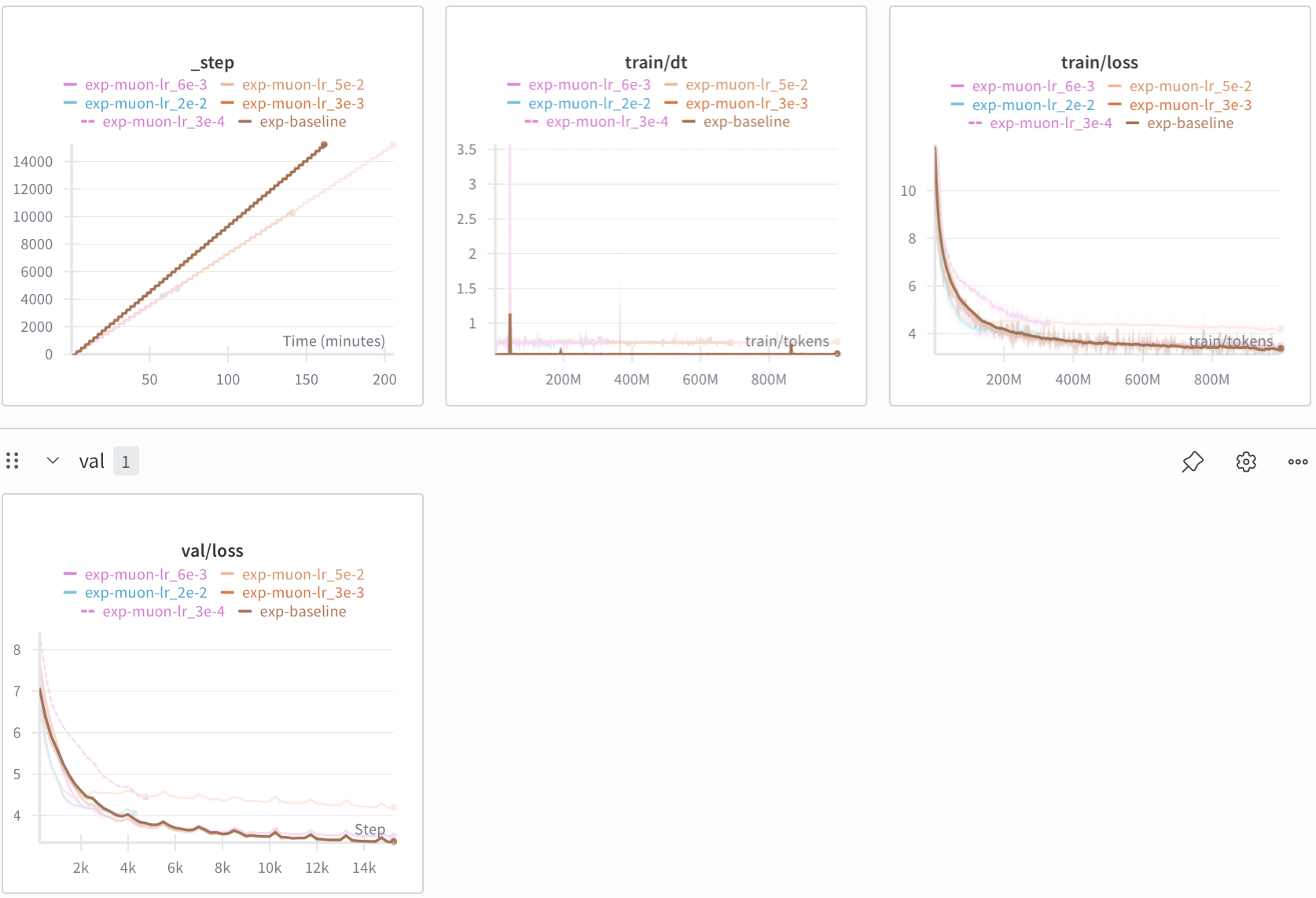
From the results, AdamW + Muon is about 33% slower than our AdamW baseline (this is already widely known; it compensates with much faster convergence). I tried multiple LRs including the recommended 0.02-0.05 range as well as lower. 3e-3 worked best with my setup but still had worse performance than baseline. Although, notice how the lr=0.02 curve seems to converge quickly and then lose its momentum around step #2000. I suspect this is caused by weird convergence numerics? I tried to debug this but given I am behind schedule, I decided to defer debugging to another time.
Multi-Token Prediction
While looking at MTP's results (used by Deepseek V3), I realized it works better for larger models. At my 1B model size, it likely won't make a dent.
Still, for the audience, here are the results with 1 extra token predicted with 0.1x weighting to the auxiliary loss:
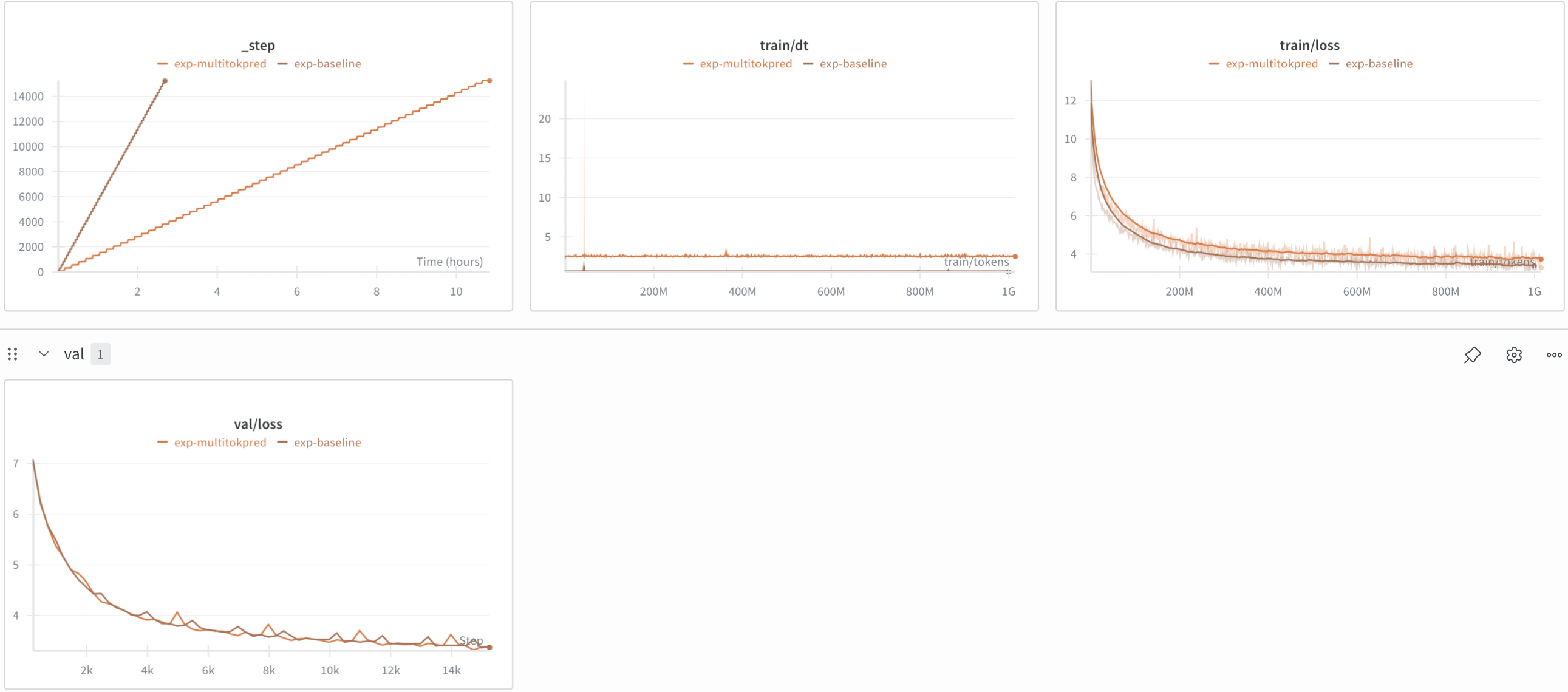
Much slower and less performant on val loss. I think as the model size scales, the MTP head becomes less and less of an overhead, so it might make more sense in larger model training.
Architectural Changes
ReLU²
I showcase SwiGLU vs ReLU² below.
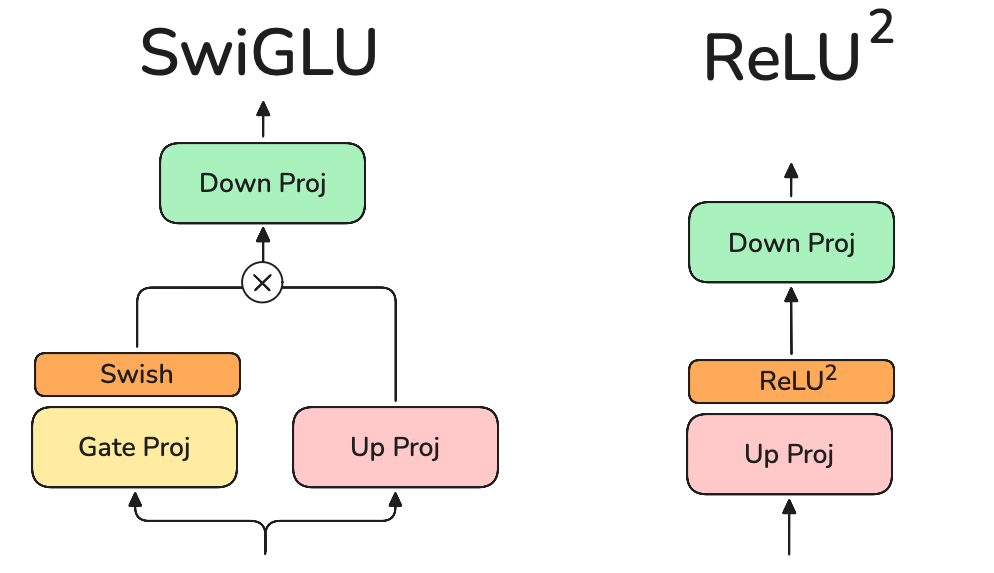
Llama3 uses SwiGLU which uses three linear layers while ReLU² uses only two. This should give us a boost in performance. However, while I like performance gains (and weight memory reduction), the FFN is supposedly where the model stores its knowledge and given my target domain, I am hesitant to bring this in.
Nevertheless, here are the results versus baseline:
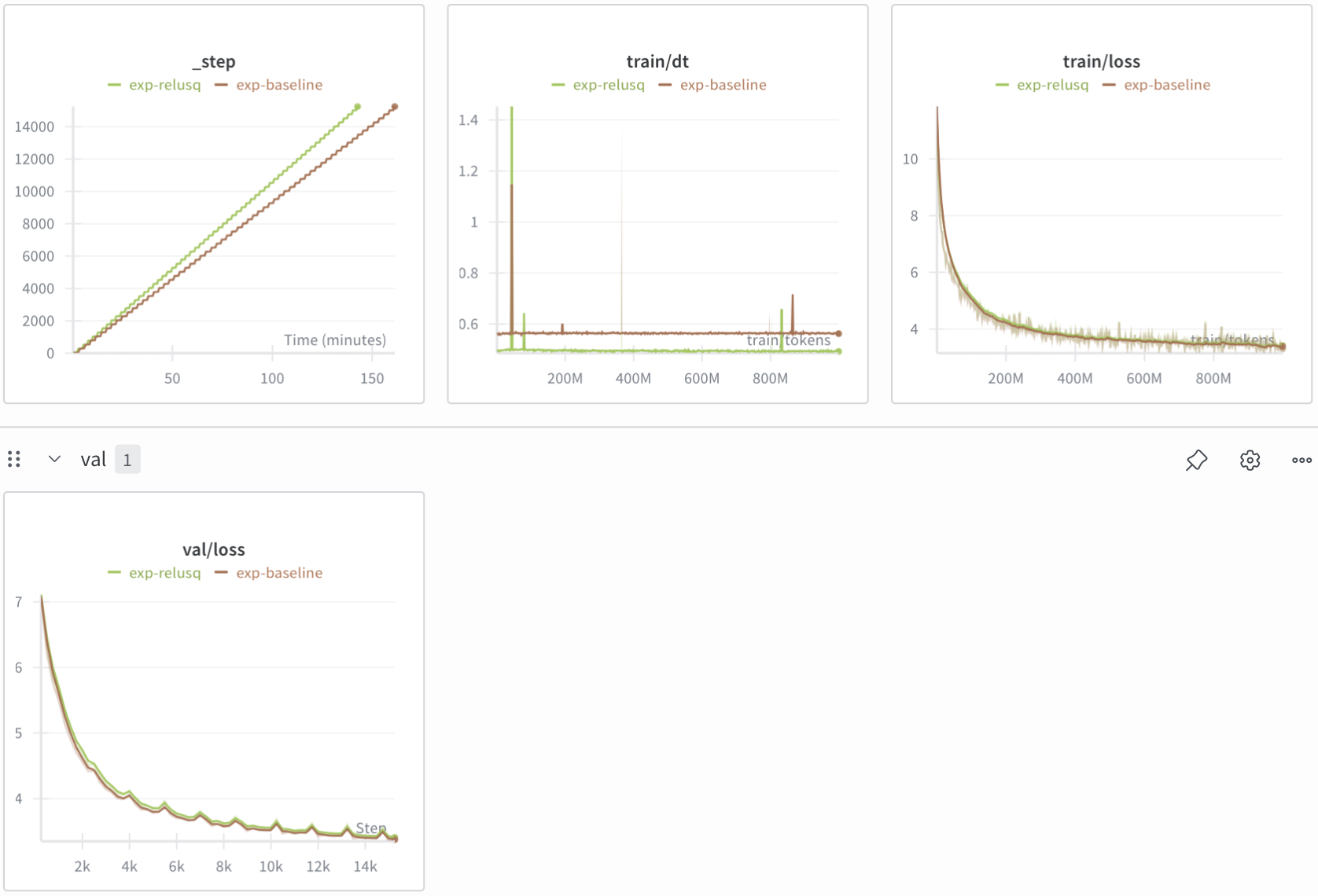
Results are close, baseline loss is a bit better but ReLU² runs faster per step. ReLU² might potentially be better efficiency-wise but I'd need to measure downstream evals to tell for certain.
QK-Norm
The following article by Ross Taylor is great at providing intuition on why the idea works. It boils down to making training stable again by avoiding exploding attention logits.
The implementation behind QK Norm is very simple: add a LayerNorm to Q and K before computing attention.
I wish I logged attention logits as well to showcase its effectiveness, oh well, here are the results:
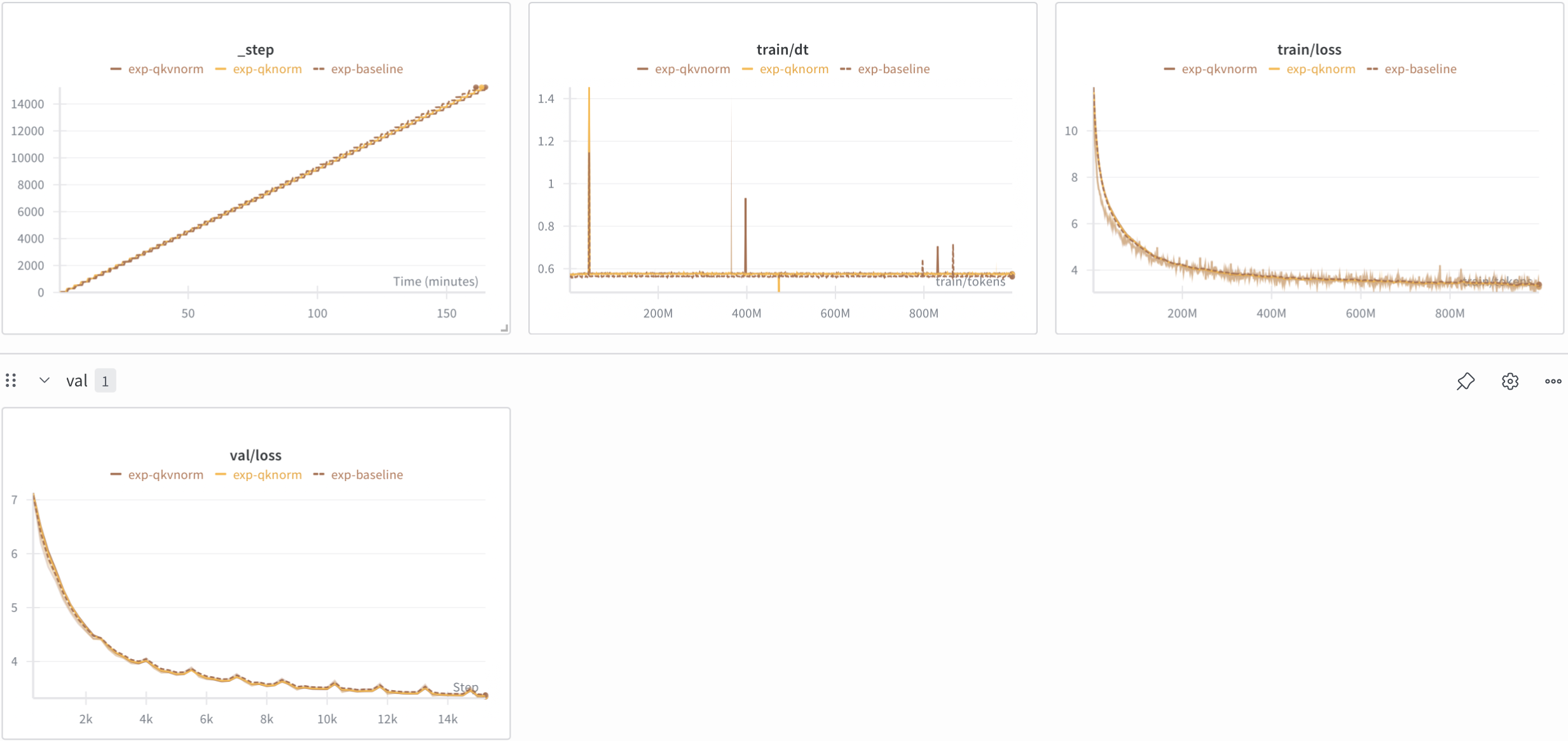
Very close to baseline in performance (slightly better) and 2% slower. W.
Softcap
The Google Gemma team developed Softcap to limit the maximum logit produced. It's different from QK-Norm because QK-Norm doesn't explicitly cap the logit value but other than that, they have a similar effect.
Couldn't we clip the values using a piece-wise function instead? Softcap is continuous and therefore, differentiable. Here is softcap with a changing cap t for a range of logit values x.
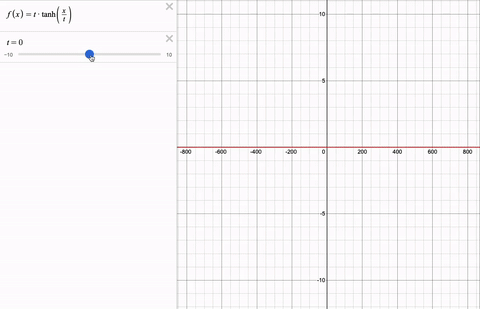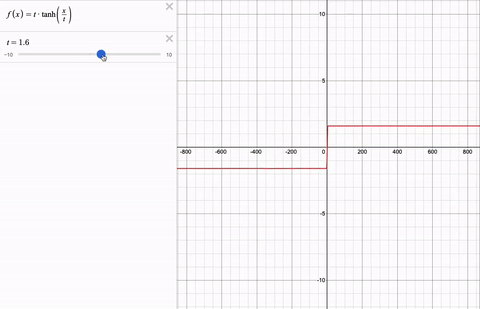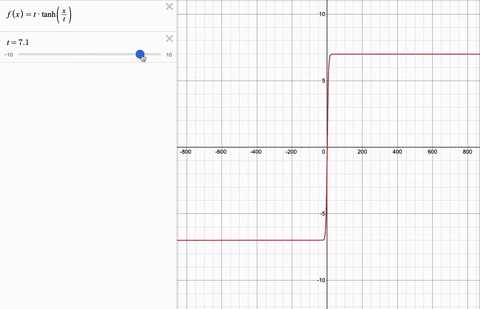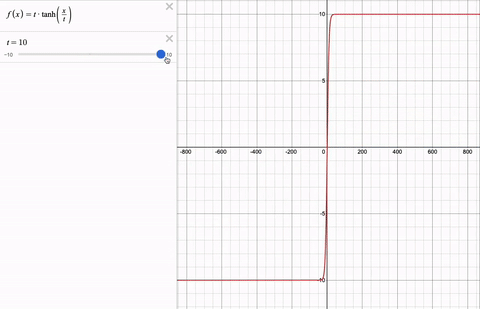
Results:
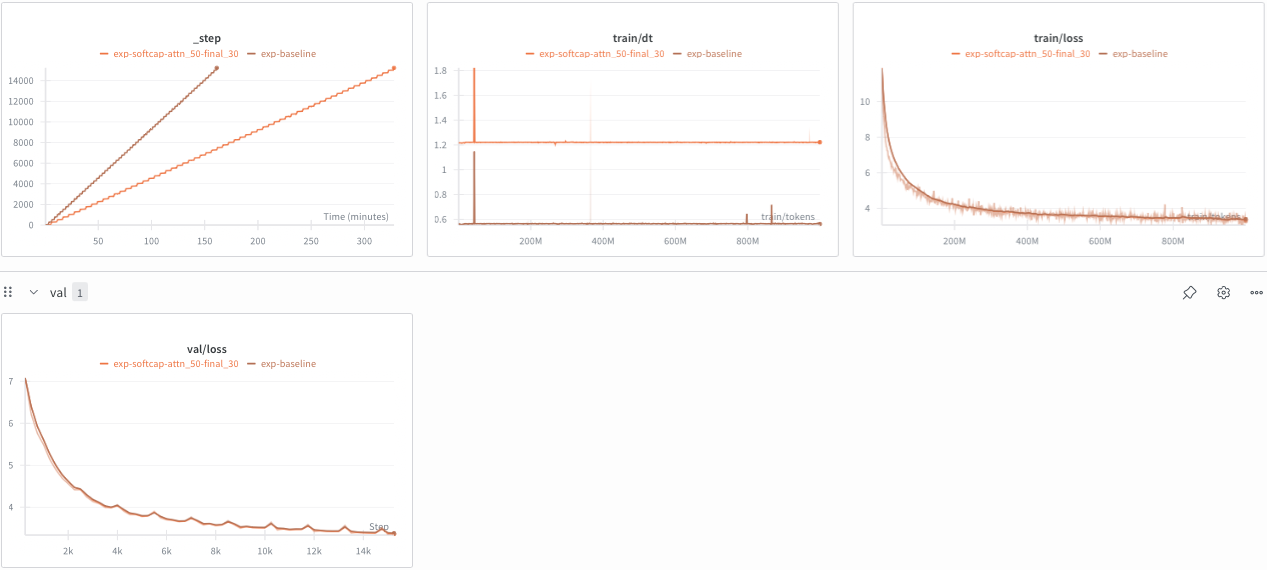
I added softcap to the softmax after lm_head (cap=30) as well as softmax after attention (cap=50). My softcap implementation is MUCH slower than baseline while being slightly better on val loss. It's likely I have a bug in implementation, nonetheless, given our model is 1B, it would make sense to only keep QK-Norm to tame logits.
Multi-Head Latent Attention (MLA)
MLA is an attention innovation by the Deepseek team. I'd recommend reading this article by Eryk Banatt to learn more. At its simplest form, the insight is to compress the attention input into a low-dimensional latent vector, where the latent dimension is much lower than the original. When attention needs to be calculated, this latent vector is mapped back to the high-dimensional space to recover the keys and values. It's not a train-time optimization per se, rather it leads to huge KV cache savings during inference.
If you are curious, here is the architecture diagram from the paper linked above:
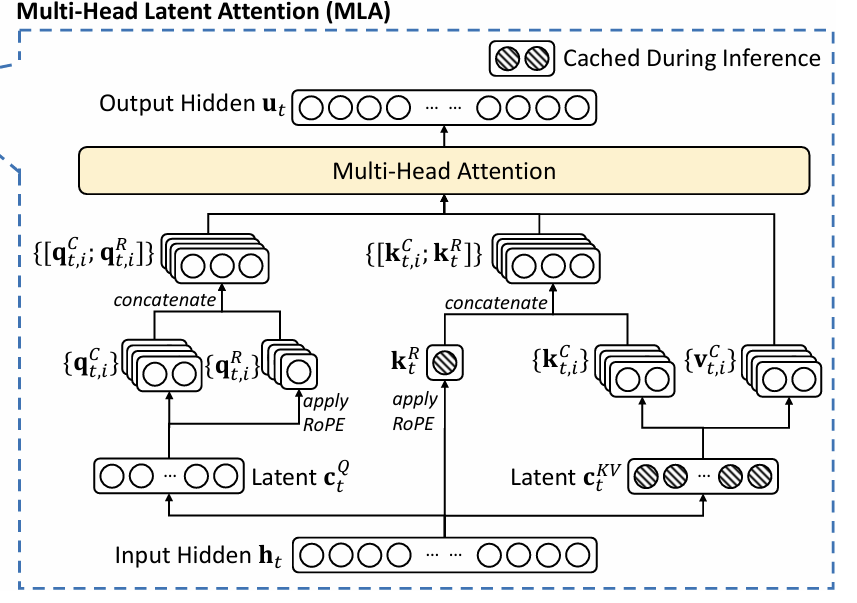
And don't worry if it's not very clear at first glance, it took me some time to grasp this.
Note: I use the full 1B model for baseline vs MLA.
Results:
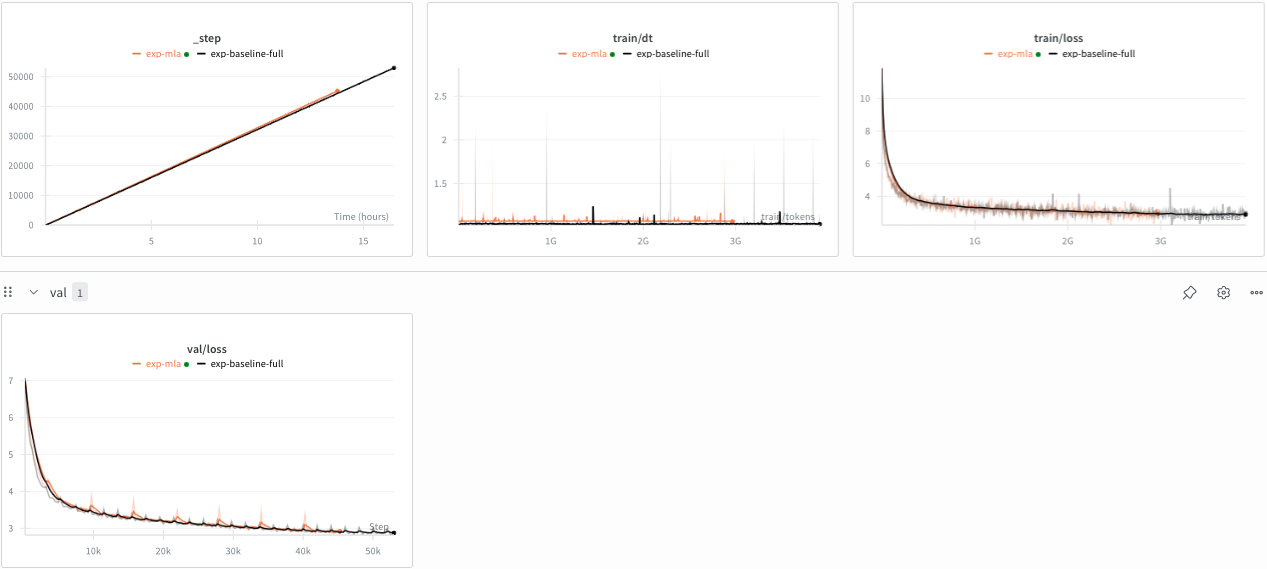
Slightly slower, validation loss on-par, this could be a good optimization for faster inference!
MixAttention
Like MLA, MixAttention's power shines during inference. The idea originated from Character AI's inference optimization blog and was later scienc-ed by the Mosaic team here.
The idea leverages interleaving local attention (SWA a.k.a Sliding Window Attention) and global attention (Group-Query Attention) as well as reusing the KV-Cache. My specific config is similar to MA-Pairs from Mosaic's paper. 16 layers, 3:1 ratio of local to global attention, every second local/global attention shares KV with the previous local/global attention layer respectively. SWA uses a sliding_window_size = 512. The following image shows my exact decoder layer setup.
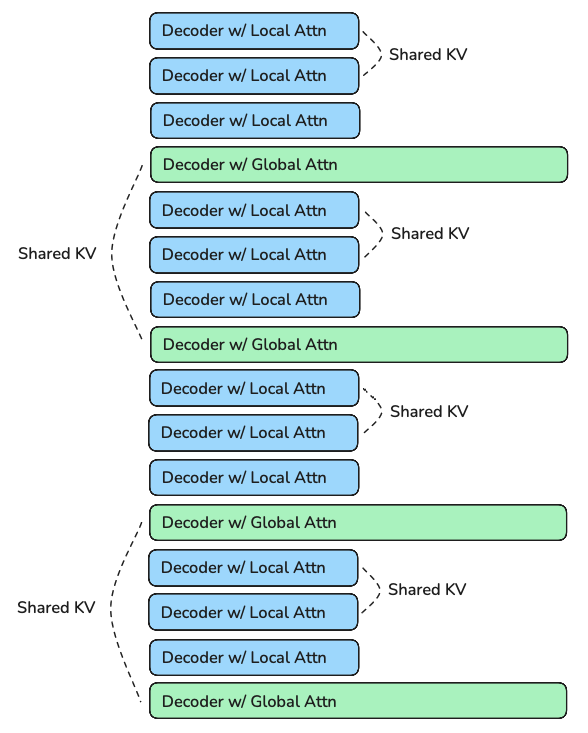
Note: I use the full 1B model for baseline vs MixAttention. I am about to go out for dinner which means a quick run is not as important :)
Results:
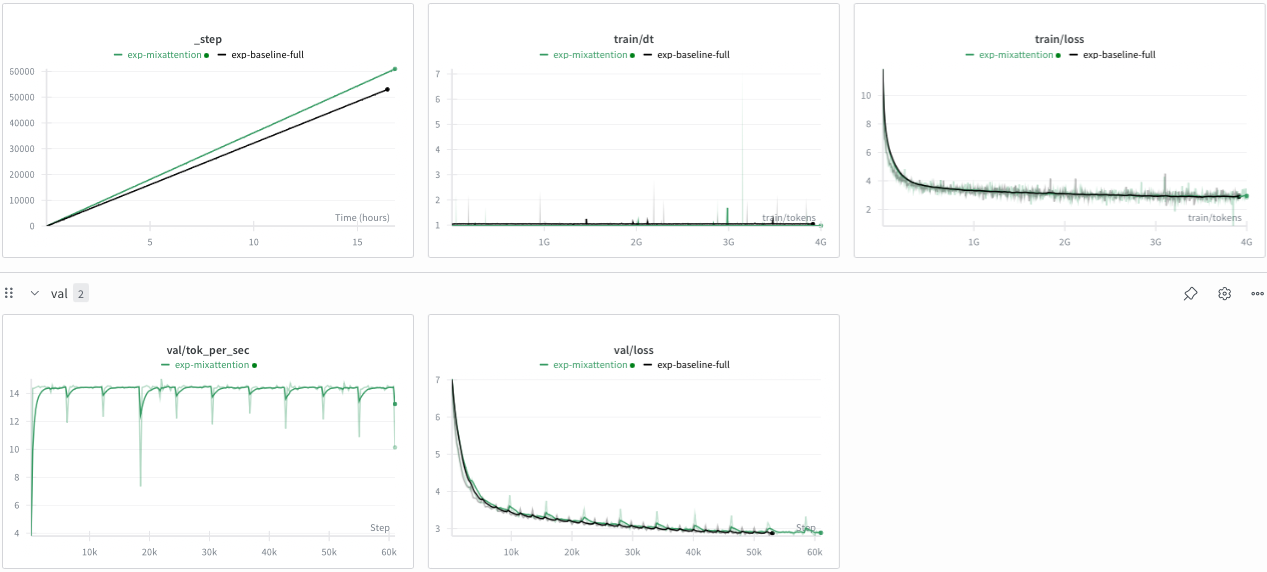
It converges slightly worse (token for token) while being meaningfully faster for training. Therefore, MixAttention seems to be the winner for now.
LIV Convolution
I covered LiquidAI's LFM-2 architecture a while back. These models are highly inference-optimized, while maintaining strong eval capabilties which piques my interest.
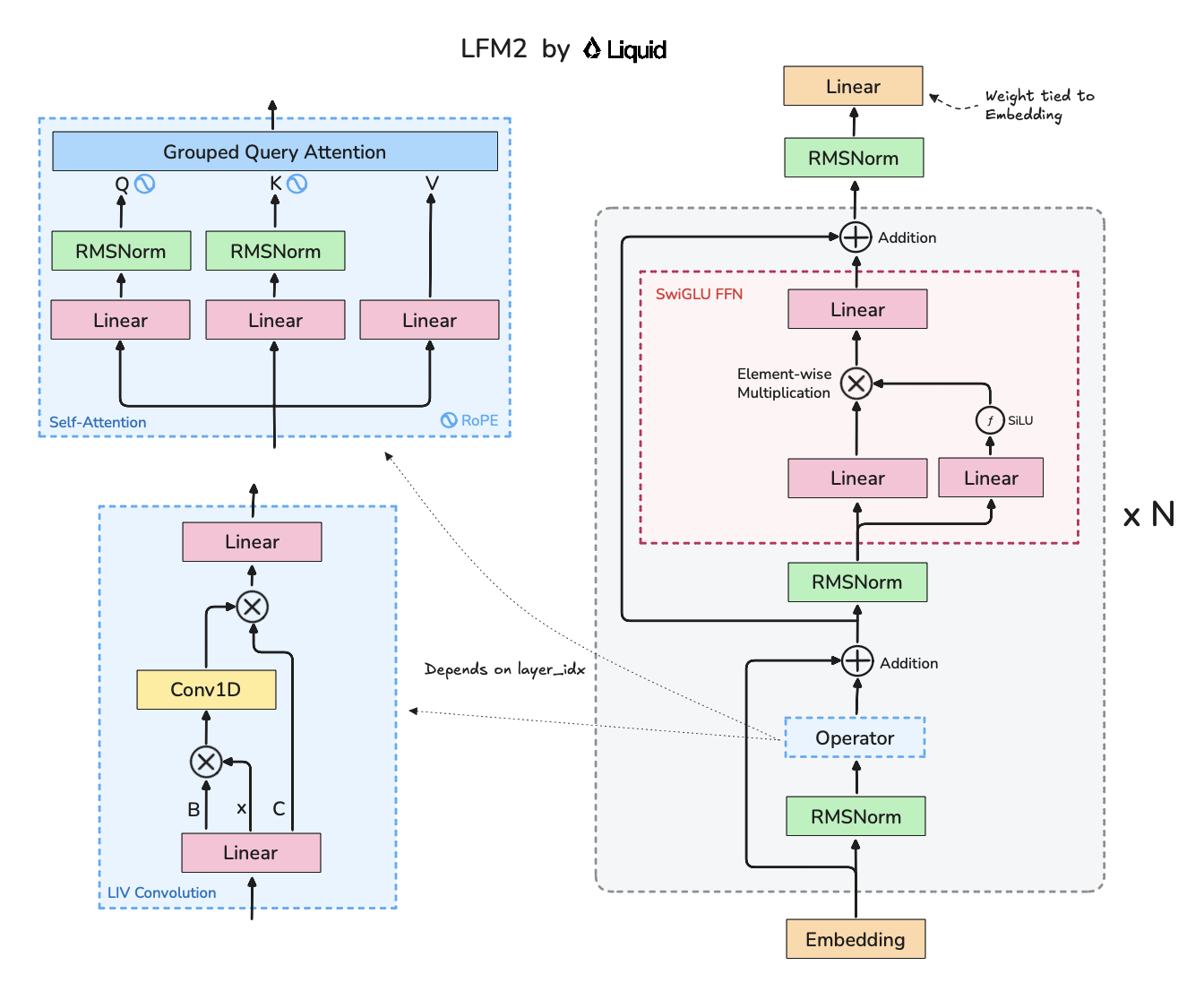
These are the results I get for a slightly larger LFM (1.6B vs 1.2B) model:
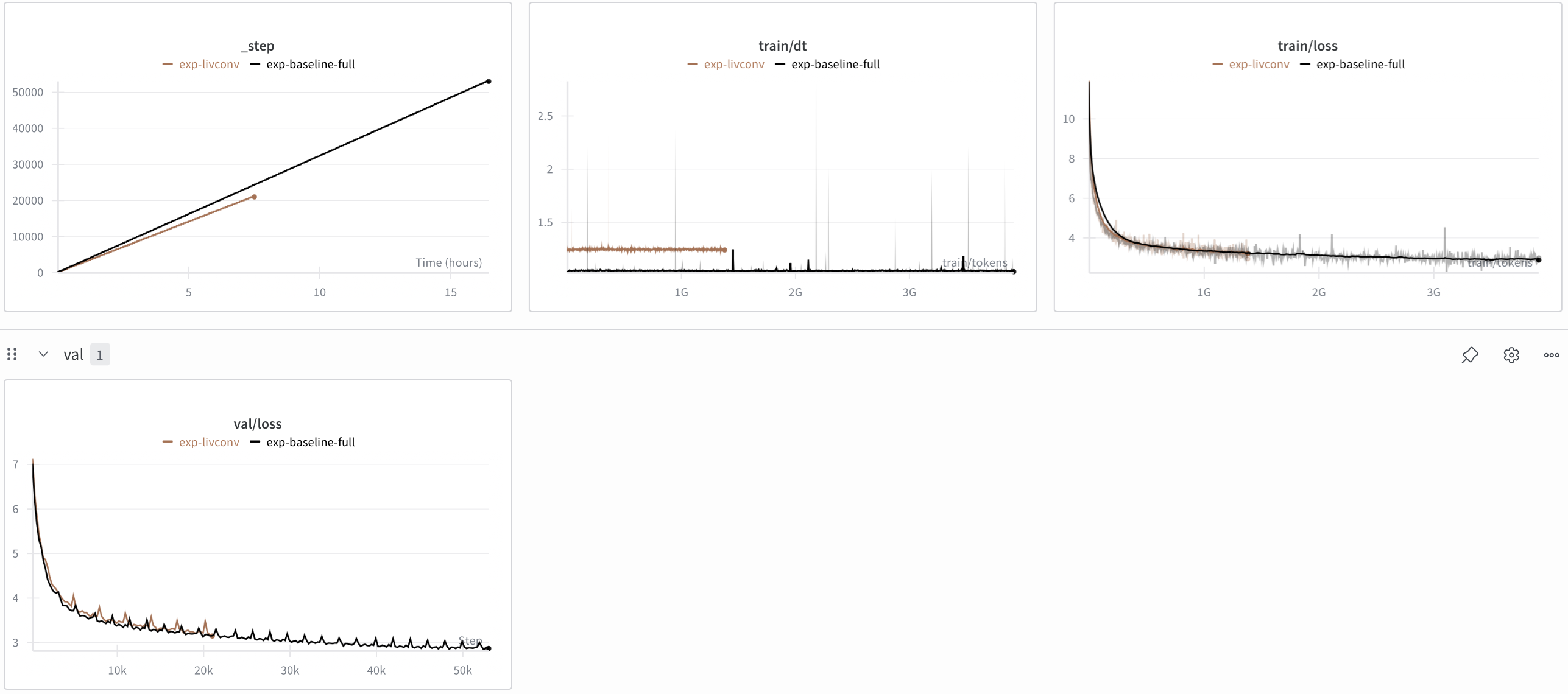
While I prematurely had to end the run given budget constraints, I have enough to decide which Attention variant I want to use. LFM is a bit slower to train (much faster on inference) which is fine given it's a bit larger than my baseline. However, I notice it converges a bit worse than my baseline which is my main concern.
Conclusion
This was a beefy experimentation blog and I thoroughly enjoyed the process. To conclude, in the next blog, I'll be training the base 1B model on 8xH100 with cross-doc masking, QK-Norm and MixAttention. I'll also be setup up an eval suite and training schedule to tune context length.
P.S. about the refactor
My codebase was getting sloppy with footguns. My refactor attempts were feeble. Alas, Gemini 3 Pro comes to the rescue right on cue.
We co-designed the codebase arch where hydra-powered yaml configs allow me to make inject modular changes into the builder pattern for main components like model, optimizer, dataloader. For logging, I make use of the callback pattern which calls log_to_wandb, save_checkpoint, etc at different step counts produced from my config, which declutters my main loop!
I came out of the debugging trences with mounds of experiment corpses all around me:
Victorious, but at what cost?
To debug, what all did I not try? Logged all kinds of metrics, I tried increasing weight decay on non-embedding params, switched logits to fp32, trained new tokenizers, added a val dataset which used a different subset, dropout on attention / mlp and what not. I had a feeling none of these were the underlying cause given loss < 2 is impossible at 2k steps.
There's only a few places that could be buggy: model, loss objective, dataloader, loss numerics, and tokenizer. Finally, my sentence was overturned when I switched out my custom tokenizer for GPT-4's and my complicated sharded, checkpointable dataloader for a simple one. The dataloader was definitely buggy.
I don't need a custom tokenizer right now given I don't have custom datasets (FWIW GPT-4 tokenizer is better at my target task too lol) yet and I plan to work on a high-performance dataloader after I figure the rest of my architecture out.
Omkaar Kamath