The Illustrated LFM-2 (by Liquid AI)
Attention blocks get all the attention nowadays. While a bunch of companies tried the model-layer biz model, only a few have cracked differentiation. Others have succumbed to loss (of mindshare) and failed fast.
I remember watching Liquid's 2023 demos and not understanding the play at hand. However, in 2025, they are making big strides (pun unintended) in the edge inference market. They have done a great job with alternative architecture exploration with architecture search.
Earlier, most hype models used GQA + full attention on every layer (looking at you llama-3). More recently, I am spotting more hybrid attention configs (GPT-OSS coming out with full + banded attn on alternate layers).
FWIW Character AI came out in 2023 talking about hybrid attention for faster inference which is a testament to noam's intuition.
While those are examples of hybrid attention, Liquid AI is exploring hybrid architectures (interleaving attention + something). I was pleasantly surprised at ICML'25 to hear their use of 1D Conv blocks instead of attention.
I will be fleshing out this architecture here. I also drop some functional pytorch code to help you understand better.
Llama-3 Architecture refresher
I like Llama-3's architecture because it is very popular and fully standardized now. Here's my illustration:
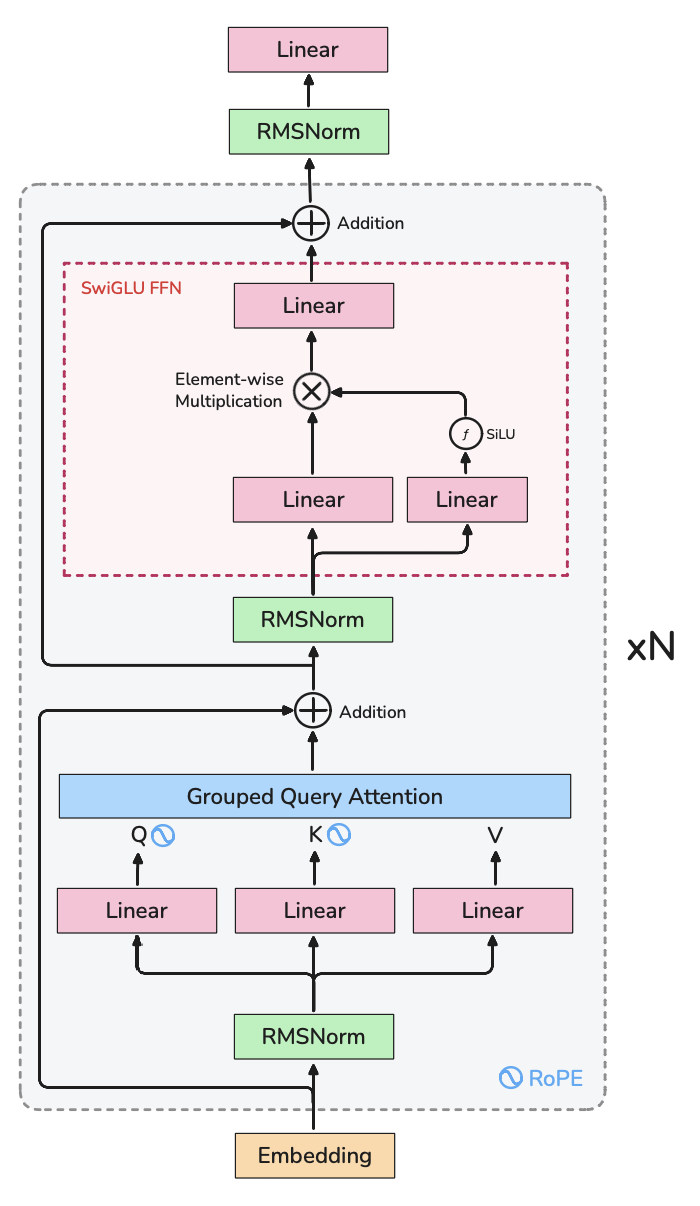
To summarize, the key details are: Pre-Normalization, RMSNorm, Rotary Positional Embeddings, Grouped Query Attention and SwiGLU FFN.
LFM-2
This model was bred (via evolutionary search) to run on target hardware like Samsung Galaxy S24 Ultra (Qualcomm Snapdragon SoC) and AMD Ryzen (HX370) [1].
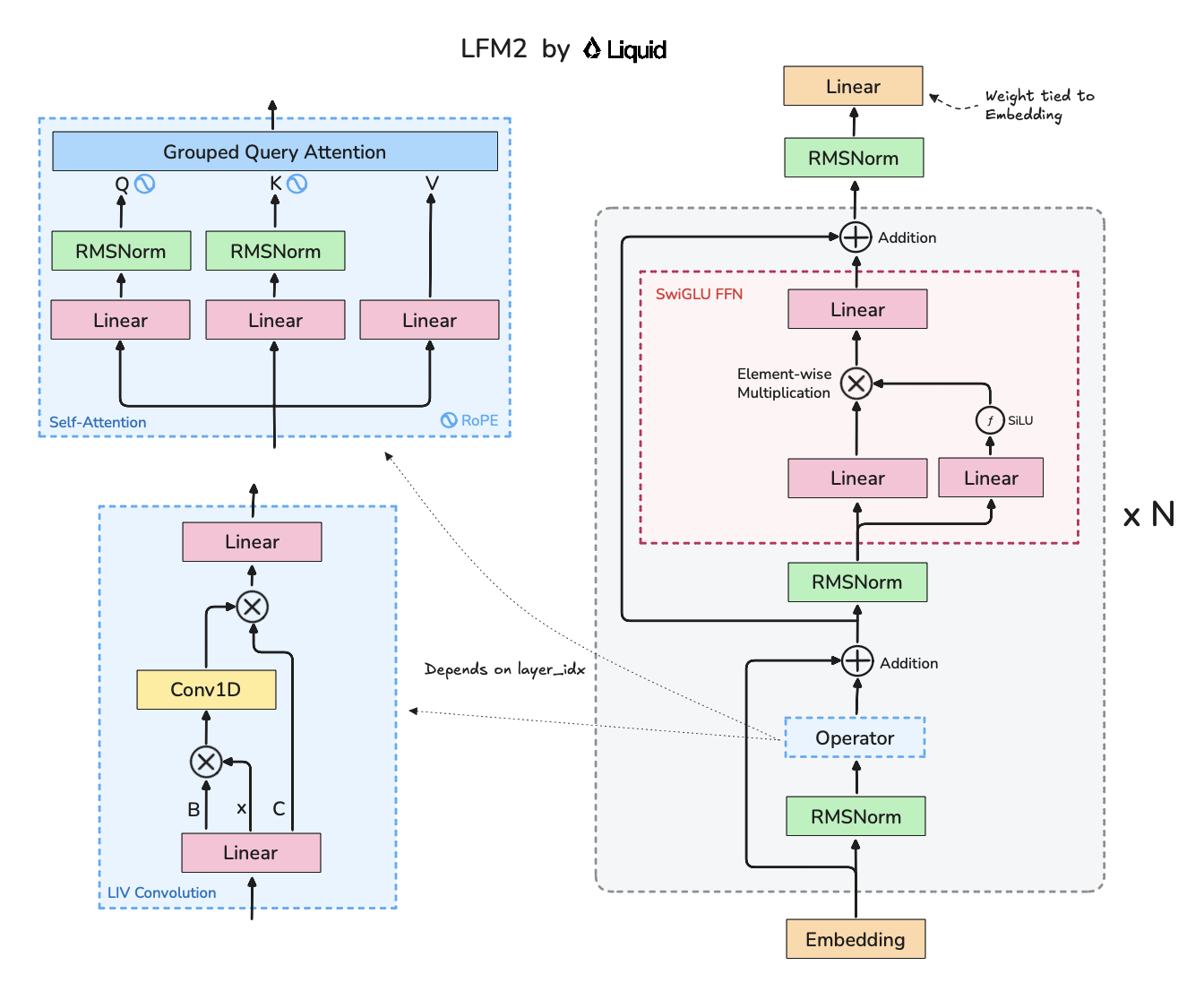
Key differences from Llama-3:
- Attention does not run on every layer, instead only 6 of 16 layers have attention. The remaining 10 run something called LIV convolutions which is a 1D convolution layer (with kernel size = 3) sandwiched between two gates. Convs are much more compute-friendly.
- QKNorm used in GQA, probably to stabilize training
- LMHead (last linear layer outside the decoder blocks) has its weights tied to the embedding layer. This is common in models that try to reduce param count as the embedding and lm_head layers are usually the largest single weights in any LLM.
Check out these graphs showing prefill and decode speed on different models (Source: Liquid's blog).

On CPUs, the bottleneck is usually memory bandwidth, not FLOPs. Full attention (like llama3) repeatedly streams a growing KV cache during decode, thus latency scales with context length.
LFM-2’s short, gated 1D convs avoid that: per token it only needs a fixed-size kernel that fits in cache and SIMD vectorizes well. The few GQA layers seem to be enough to alow global mixing and keep contextual quality up.
Feel free to check out my working implementation of this model.
This post has been inspired by Jay Alammar, Nishant Aklecha and Phil Wang
By Omkaar Kamath