Toddler VLM learns how to navigate
TLDR: I built a tiny embodied-navigation benchmark for VLMs, found that small instruct VLMs fail badly, and learned that my biggest bottleneck was probably perception/data quality rather than RL itself. I ended up getting the best results from fine-tuning on synthetic data I produced.
Recently, my mind has been occupied by the idea of long-horizon RL and multi-modal language models (I call it MMLM henceforth) learning behaviours from games. Papers like AI Gamestore propose to evaluate AI systems through human games inspired that.
Imagine a general LLM being able to play chess (which requires long-horizon planning and plotting) as well as AlphaZero. AlphaZero is only good at chess, but the MMLM can help you with homework, write hilarious haikus and also obliterate me in chess (low bar).
This objective might seem moot at first but my hypothesis is that any model capable of doing such a broad range of activities well truly must be intelligent. Models should be able to learn and reason about market dynamics through games like Tycoon, Social Dynamics through Among Us, etc. I wanted to do a much smaller scale experiment of this, so I made an eval to assess a VLM's visuo-spatial reasoning.
You can find my code here: https://github.com/omkaark/grid-walker-eval. Be warned, I prioritised research speed over code quality, many parts of this research code are AI generated with manual editing after. If you want more stable code, checkout production frameworks like verifiers, TRL, etc. or wait for my artisanal RL framework to release.
Building the Eval
The eval idea was very simple. Given an NxN grid, the objective is to navigate towards and land on the golden square. There will be a few blocks as obstacles and a wall to stop you from falling through.
This is what the game looks like:

You can actually play the game here - https://omkaark.com/grid-walker.
The game is fully HTML/CSS/JS which makes it hostable basically anywhere (including the link above, just point playwright to it).
I can't afford to try it on the frontier models, so I hooked it up to openrouter and tested different models like Bytedance's Seed 1.6 and Qwen-VL 235B.
They were not great at this task and it surprised me. I don't think labs currently have any conviction or evidence that this capability has economic uses to waste precious training flops. So, I decided to give it a shot and hillclimb the eval.
The harness is also pretty simple, the models get a system prompt explaining the game and the current state's image via playwright screenshot. They get to output either forward N (to go N steps forward), right or left (to turn in the same spot). Then, the next stat's image is provided and so on till the game is won (standing on gold spot) or MAX_TURNS happens whichever is earlier.
The model gets to see its previous actions along with previous images. I was considering leaving previous images out (which would let me increase my rollout batch size) but I am hoping it learns to use historical positions to explore new paths.
I will list the baseline model vs checkpoints on this eval in the last section.
This is the output logs of my eval being run with Bytedance's Seed model. It's hilarious to watch the model coming close to the goal and moving on.

Anthropomorphistic View
Watching a VLM play the game feels uncanny. Different VLMs I had different behaviours. Chinese models for some reason were conservative and moved one step forward at a time. American models took larger steps and often found themselves running into a wall till the game timed out. Both models had the tendency to oscillate between left and right as if panicking about what to do next.
Note, these are empirical observations.
Here's a model running into a wall one jump at a time.

I found it really funny when models had the objective right in front of them but still chose to go around the block, waste a few steps and then coming back to the spot.

Qwen3 VL 2b was having a pretty hard time but showed an understanding of the task on easier tasks. I like visual evals because I get to visualize exactly what the model has to work with.
Attentiography
This is a visualization of what the VLM is "seeing" using attention scores.

After looking at a bunch of these, the model seems to not attend to many of the patches on which the gold squares lay. Is this evidence enough that the model is not ready for this task? Not sure if visualized attention scores have any meaning.
Approach 1: Simple RL
Since the model is naturally non-thinking, I wanted to see how far I can push it to doing this task successfully and reliably. It's a hard problem to look at an image and without any reasoning giving an action to move towards the goal. My goal is to run RLVR on this task.
One blocker in this task was the fact that the base qwen3-vl-2b-instruct (which I will henceforth refer to as "the qwen model") had no situational awareness. It kept running into walls and not self-correcting / oscillating left and right. RLVR on a weak model like this will basically lead to very sparse rewards which is inefficient. The model should learn to move multiple steps at a time and in general, should know ideally how to get to the gold square. So... we SFT.
SFT
The whole point of SFT at this stage is to nudge the model to output formats that perform better on RL tasks. My constrained task makes SFT easier as I can use basic algorithms to generate data containing the best route from current point to gold square while avoiding blocks.
I generated synthetic data of efficient paths, collected images and ideal actions and LoRA finetuned the model on it. Note that I plan to use vLLM as my inference engine for RL rollouts later, it does not support a vision encoder LoRA and so, I only finetuned the text decoder's linear layers, and yes, this does handicap my efforts a bit.
Reinforcement Learning
I'm guessing the audience of this worklog will be split between those who understand RL and those who haven't had the opportunity to. So, I'll give a simple intro to RLVR.
The point of RL
The objective in fine-tuning is to guide the model to predict the next token with a given dataset. RLVR (Reinforcement Learning w/ Verified Rewards) is about exploring the solution space of a task, sampling many solutions with a high-ish temperature and getting many answers which then get scored using a verifiable reward. Rewards like whether the player is on a gold square or not are considered verifiable. For the answers which are correct, token sequences are encouraged while the converse applies for wrong answers.
My environment is set to be deterministic (same obstacle and goal placement) given the same seed. So, we run 16 rollouts with the same seed on our environment and sample at a high temperature (0.7 in this case) to let the model be more creative in its answers... all in the hopes that it finds more interesting ways to get to the right answer. For example, the model does not see the gold square in its view, instead of going forward which the base model does, it reflects that it has to explore the map and turns right or left.
Fine-tuning is more efficient per flop but RL generalizes better and finds more interesting behaviours which would be hard to encode in a finetuning dataset.
GRPO as an RLVR algorithm
I use the GRPO family of objectives; GRPO was introduced in Deepseek Math and later used in Deepseek-R1-Zero. This is the algorithm formulation (use the scrollbar):
$$ J(\theta) = \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left\{ \min \left[ \frac{\pi_{\theta}(o_{i,t} \mid q, o_{i,\lt t})} {\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,\lt t})} \hat{A}_{i,t}, \; \text{clip}\left( \frac{\pi_{\theta}(o_{i,t} \mid q, o_{i,\lt t})} {\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,\lt t})}, 1-\epsilon, 1+\epsilon \right)\hat{A}_{i,t} \right] \;-\; \beta\, D_{\mathrm{KL}}\!\left( \pi_{\theta} \,\|\, \pi_{\mathrm{ref}} \right) \right\} $$
where
$$ \hat{A}_i = \frac{r_i - \mathrm{mean}(r_{1:G})} {\mathrm{std}(r_{1:G})} $$
Now, I'll proceed to briefly explain each part.
When I first saw the equation, I almost gave up. Having spent some time working with it though, it is much simpler than it looks. The clip/min part took some time for me to wrap my head around and visualize.
Since objective function needs to be maximized and traditional DL requires loss to be minimized (gradient descent), we simply negate the objective function to get our loss value. The KL divergence term is important to not have our model's distribution shift too far off from base model, this helps preserve the model's generalizability.
Dr. GRPO
"GRPO Done Right" or Dr. GRPO argues that GRPO has two biases:
- The 1/abs(o_i) normalizes each rollout by output length. When advantages are positive, shorter responses get larger gradient updates, so the model biases towards short answers when correct. However, when advantages are negative, the model ends up punishing shorter incorrect responses more than verbose ones leading to longer incorrect responses.
- std(r_1:G) in advantage calculation ends up biasing the model towards very easy or hard problems. When the model gets all the rollouts with very high or very low reward (very easy or hard problems), the std dev is low, which boosts advantage and ends up awarding larger gradients.
This paper simply scrapped them and saw an improvement. In my current setup, I actually only output 6-10 tokens per response. Output length normalization will not be helpful. Scrapping std(...) would make sense given I start off with a very low win rate. I scrapped both.
Infrastructure
This is my favorite part. Instead of going with a pre-made framework, I decided to write my own RLVR loop. While implementation requires treading carefully, the general steps are easy at a high level.
Companies like OpenAI / Anthropic likely write the full stack themselves from inference to RL infra to model code. In the interest of my time, I used vLLM as my rollout engine and Huggingface as the finetuning backend.
The following is how my two-phase RL loop works. Two-phase because Inference and Training happen on the same GPU.
The diagram should be pretty self-explanatory. There are caveats like using vLLM sleep mode = 1 and load/unload lora quirks amongst other things which you can find in the code.
Results
Before I give out the results, I'd like to remind you that completing the game in 10 turns is an ambitious endeavour. This means the model not only has to learn to explore the map, but also jump many steps at a time to conserve turns.
Seed Flash 1.6 which is a thinking model scored 3/20 on a 8x8 grid with three blocks and seeds 0 to 19. Qwen/Qwen3-VL-2B-Instruct scored 1/20 under same conditions. My RL'd qwenny trained on 100 steps scored 3/20.
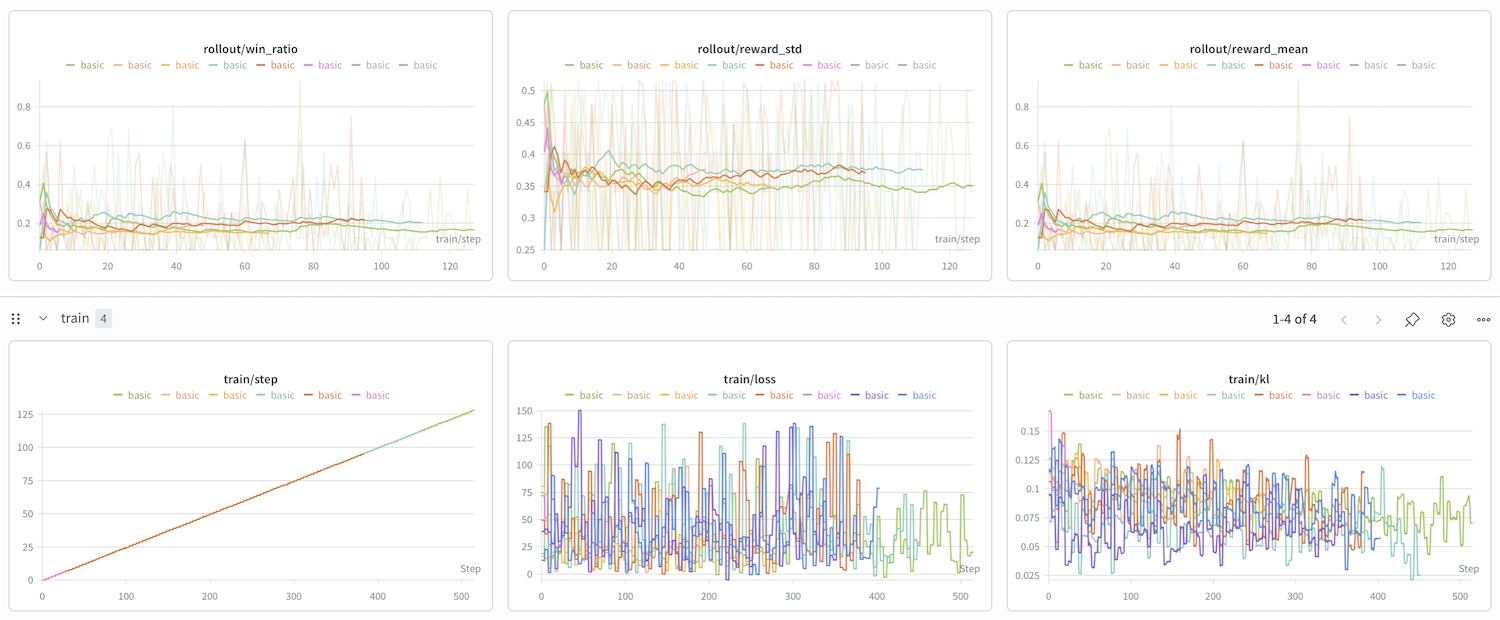
This dashboard shows a stagnant reward being assigned on different RL training runs. There's multiple of them as I kept hitting edge cases in my environment and my runs kept erroring out. I had to run with n_group=1 and batch_size=16. This is not ideal as the point of GRPO is to have multiple groups and larger rollouts.
Approach 2: Deepseek R1-Zero type RL
Deepseek R1 Zero RL-Zero applied RL directly to a base model without SFT and showed reasoning behaviors emerging naturally. It sounds counter-intuitive but they made it work. The 2B model is an instruct so I suspect it should work, although the base instruct model is very reluctant to output
I assigned rewards for think tokens but given rollouts very sparsely include
Approach 3: Eliciting Chain-of-Thought via SFT + RL
RL'ing on the answer itself (Approach 1) is too simple of an idea and so, evidently has its limitations. I need my model to yap before spitting an answer. I need to awaken my inner noam and make this model think™.
Thinking Mode™
I am not an expert in training thinking models, so I went with my intuition and the scraps of knowledge I picked up from reading different papers. I will first need to generate synthetic data of thinking traces before each model step. Then, I will need to wrap it in special <think> tokens and SFT a model on it. Finally, I will RL like I did in approach 1 but instead of assigning a simple 0/1 for loss/win, I will also give a small reward for think tokens. Dr. GRPO will be more handy in this case.
Generating synthetic reasoning data
I have a three approaches in mind:
- LLM-based annotations: Big LLM does 1000 rollouts where it describes what its seeing with the answer in mind before hand, e.g. we know the model should step 3 steps forward, the assistant output would be
<reason>Gold square looks 3 steps ahead<reason/>'forward 3'or if the square is not in view<reason>Square not seen in view, let's explore and turn left<reason/>'left'. - Heuristic annotations: This is technically possible, we know whether the gold square is in the frame or not, we know if it's behind or to the left, etc., synthetic data of this could be crafted. Though, this would be an insane amount of work to get good data and is not quickly generalizable to other domains.
- Manually annotation: I could just sit and produce 1000's of data points for SFT... yeah, not happening.
An interesting observation when building the synthetic data generator is because my image resolution is low, the gold square is not detected even by the Qwen3-VL-8B-Instruct model. I am not sure if the encoder patch does not represent it or the decoder does not learn this property.
My idea is a mixture of all three approaches. First, we use a VLM + pixel-based heuristic (checks for gold color in frame) on the frame. If either one detects gold, very high chance there is gold. I manually annotate few different thinking chains for forward, left and right action cases, for example, "Gold is directly in front, so I move forward". Simply return that trace along with optimal action (we know this because we know player position and end goal already). In case the gold tile is not detected in the frame at all, 50% chance the model turns in the opposite direction and 50% chance the model turns in the ground truth position. This adds some exploration behaviour into the model. To preserve quality, samples are only committed from episodes that eventually reach the goal, so the dataset is aligned with successful behavior rather than dead-end trajectories.
Once the finetune is done, the process is the same as Approach 2. I wanted to give this run the best shot, so I added rollout mini-batching to let me have 4 groups of 16 rollouts each instead of only 1 group like before at the cost of a much slower run. Let the training begin.
Analysis and Evals
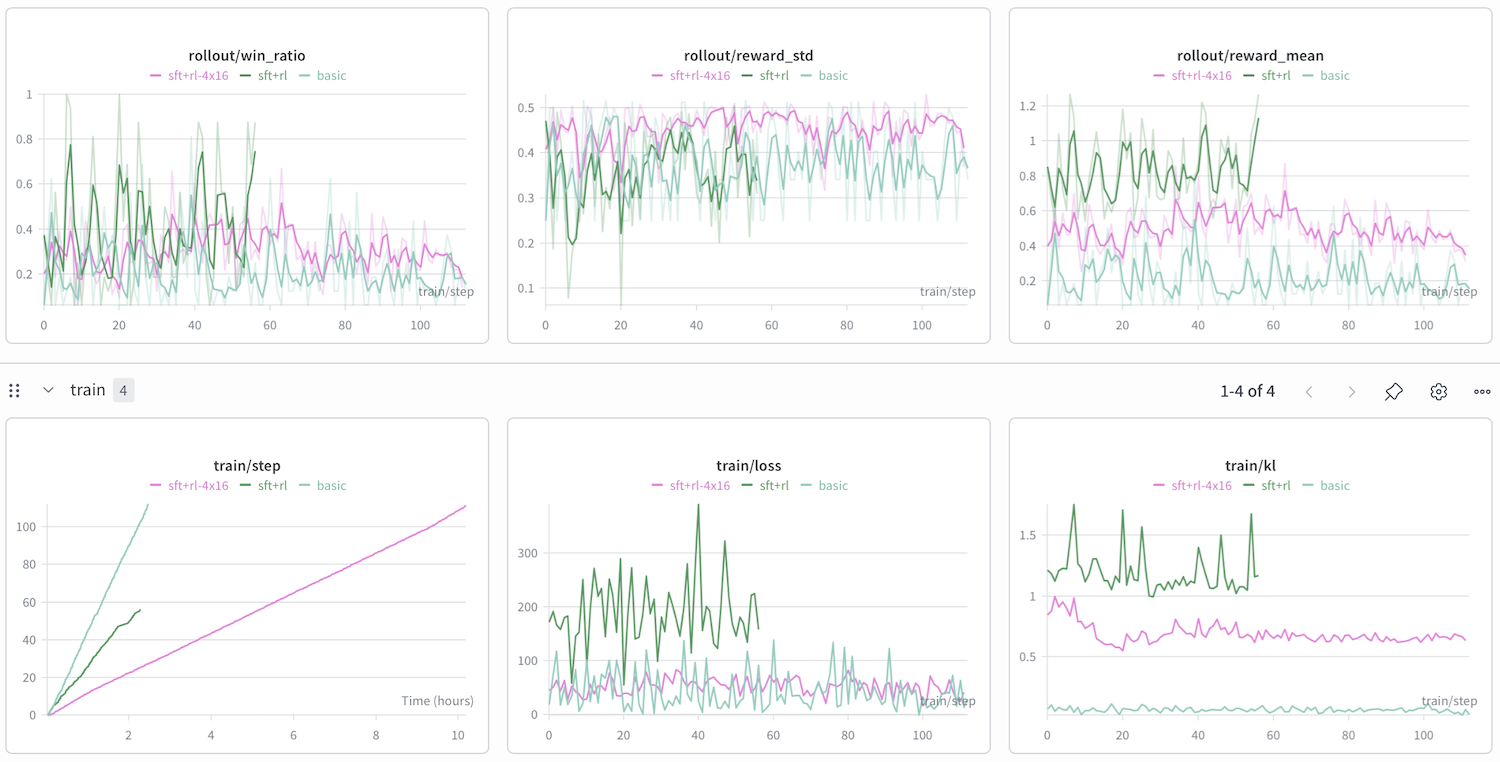
The dashboard above shows metrics for the three different approaches. Let's start of with the simplest question...
Success?
No. Success would have meant reward_mean increasing over time. This clearly did not happen in any approach.
Let me individually go through each approach from the diagram:
- Basic: Low KL as expected. Low win ratio and reward mean because RL does not really do much in this case, so behaviour is same as base instruct model.
- SFT+RL: Since we finetuned this model a bit on non-reasoning data, the win ratio improved. Although, win ratio is very unstable. There was also a bug in my code which effectively restarted rollouts if invalid or erroroneous outputs occur. Since the likelihood of that happening is lower with easier seeds, the model completed many steps on easy seeds. Therefore, unstable win ratio. Also, running 1x16 rollouts was a rookie mistake.
- SFT+RL-4x16: This is the way god intended GRPO to be done. Multiple groups, many rollouts per group. All the graphs are much more stable. The synthetic data has clearly improved model strength.
Conclusion
Here are the final scores of each approach on my eval (8x8 grid, 3 blocks, seeds 0-19).
- Base Model: 1/20
- Basic Policy: 3/20
- SFT+RL Policy: 4/20
- SFT+RL-4x16 Policy: 8/20
The last policy performed best, but I changed several variables at once, so I can’t cleanly attribute the gain between reasoning-SFT, rollout grouping, and stability fixes.
I'd like to thank Callum Sharrock for giving me some of the ideas I ended up experimenting in this work.
Where did I go wrong?
I think the assumptions I started with itself were wrong. The VLM not being able to detect the gold square even when it's right in front is the main problem. Either I should have finetuned and merged the vision encoder before starting all these experiments or I should have used a higher image resolution. I also realized if I had done the token budgeting math earlier, I could have possibly increased resolution and compromised somewhere else (smaller mini-batches, smaller seq len, etc.).
Something else confusing me is even though sometimes there is a lot of attention on the gold patches, the model moves in a different direction. This seems to me more like the model decoder is at fault too. This would also explain part of the reason why with the SFT reasoning data produced the best eval results.
I expand a bit more on this in my reflection below but I shouldn't have started experiments while building the infra side-by-side. Also, vibe-coding critical parts was a bad idea, it ended up costing me more time to fix it by hand. Anyway, I learned my lesson, I want to build a high-performance RL framework next.
Blockers faced along the way
Even though I tried to Codex/Claude my way through this project, I hit many a roadblocks. I don't like reviewing 100s of lines at a time, I prefer having good / clean / readable code in important files. In data gen and other helper files, I mostly generated many lines at once and skimmed to make sure my intended behaviour is present, code quality was not super important in them for this research repo.
However, for the actual rl.py and rollout.py files, I was heavily involed in deleting and restructuring code by hand. What I learned was I need to tune my Codex skills more and spend more time planning for the LLM.
Codex is kinda inefficient when writing data prep code with a lot of O(n^2) loops and repeated cpu-heavy tokenization calls. I proposed an idea to make it much simpler so now its way better.
Having robust infrastructure from the beginning helps a lot. I regrettably did not have that and only finally cracked long-running training by the last few experiments. Having to worry about infra + experiment, slowed me down a lot and added a lot of inconsistencies in my experiment. I plan to write more robust RL infra so future experiments should be a breeze.
What's funny is I found a bug in vLLM's load_inplace argument in the load_lora_adapter API. Luckily I also found a workaround for now. If any vLLM maintainer is reading this, I also put a simple fix up that I'd love a review on.
Another learning was how many things break in long-running / high-throughput infra. I did not expect playwright timeout errors to be the cause of my run kills.