Tinker for SFT
TLDR; I had a successful finetune run with Tinker, I open-sourced the code here so you can create your own FIM finetunes.
I am working on data experiments to build a high-quality code completion model. I have a well-rounded eval ready to go. The only thing left is... spend time setting up the cloud env to run these experiments. sigh.
So, I looked through different methods.
"Ah, I have heard a lot about unsloth, let's try that!": 5 mins of setup later, I get something along the lines of "version mismatch error". Look online through the docs and I realized I can't be bothered with figuring out versioning for what was supposed to be a quick experiment :(
"Hmm... maybe TRL by Huggingface might be good?" Take the trouble to get it on my own cloud gpus and start the experiment, one GPU is getting throttled for some reason?? I'm too lazy to get another GPU node and set everything up again. "Forget it, let's go for hosted providers" I say.
Setting up GPU infra / distributed training to run data experiments is a slog. I enjoy infrastructure problems but I wanted a service where I pay them a little more than self-managed would have cost for skipping the setup hassle.
I thought maybe I can use something like Fireworks AI, but then I remembered Tinker from their LoRA article.
I initially wanted to try out DoRA (stay tuned for future article on this) but Tinker does not support that yet and TRL's FSDP with DoRA was not working straight away. So, I switched to LoRA for this experiment.
First impressions
I wanted to get setup with Tinker ASAP, so I looked through their cookbook and was a little overwhelmed. I then switched to their docs.
My self-made metric to judge a platform like this is TTFC (Time-To-First-Checkpoint) for a dummy project or how quick I can get a working SFT run to study their API. I found their Pig-Latin example in the docs helpful to get me up and running in the first 15 minutes.
In past self-managed training runs, my workflow was to get the huggingface dataset, setup a dataloader for controlling batch-size, seq-len, etc. Tinker has a Datum object (example below) where I feed one sample of my dataset along with each token's weight or in SFT's case, same as attention mask. Because it's FIM SFT, I set up my prompt tokens with this format {FIM_PREFIX}{sample['prefix']}{FIM_SUFFIX}{sample['suffix']}{FIM_MIDDLE} and completion tokens with {example['middle']}{tokenizer.eos_token}.
return types.Datum(
model_input=types.ModelInput.from_ints(tokens=prompt_tokens),
loss_fn_inputs=dict(weights=masks, target_tokens=target_tokens)
), len(tokens)
I setup a function which streams a bunch of data from a huggingface dataset, converts each sample to the datum type and constructs a batch based on max batch tokens. It's easy, I don't have to worry about OOMs / having GPUs fail midrun / getting throttled.
For my particular use case (LoRA / small model), I could get it done for a bit cheaper with self-managed if I spend more time on setup, etc. But for small experiments like this, total cost of setup hell >> the amount of money I save.
Results
One small caveat when LoRA finetuning: I use vLLM's LoRA feature for the purposes of this blog, they seem to not support the unembedding (lm_head) layer having an adapter. So, set train_unembed arg to False when running create_lora_training_client if you plan to use vLLM for inference.
To recap, for the purposes of this worklog, my goal is to LoRA SFT Qwen/Qwen-8B-Base on a ready-made FIM dataset.
Qwen-8B Base
This was the performance of Qwen-8B-Base (non-SFT) on my evals:
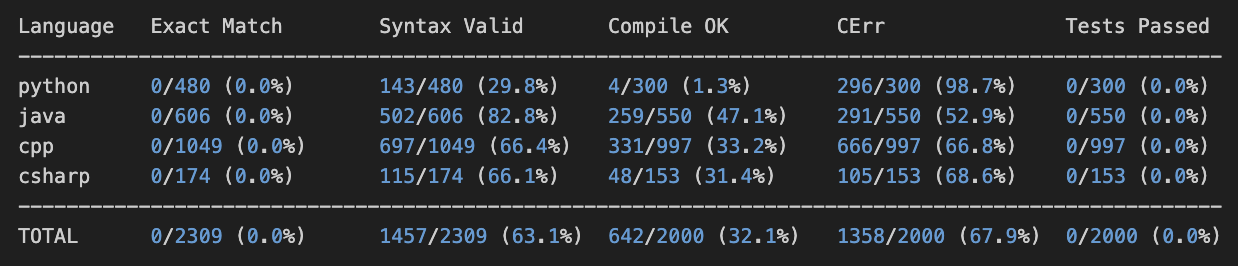
Here is a simple example completion from Qwen-8B-Base:
<|fim_prefix|>
def hello_world():
"""Print Hello World"""
<|fim_suffix|>
hello_world()
<|fim_middle|>\n\n# + [markdown] id=\"0123456789\"\n# ## 1.2. Variables and Data Types\n#\n# In Python, variables are used to store data values. You can assign a value to a variable using the assignment operator `=`.\n\n# + id=\"0123456789\" outputId=\"0123456789\"\nx = ...
This is not shocking, notice how the results have proper AST a lot of the times still. The base model is trained on a lot code and likely does not even have FIM completion training giving us mixed results.
Qwen-8B Instruct
Let's try out the Qwen-8B (post-trained model):
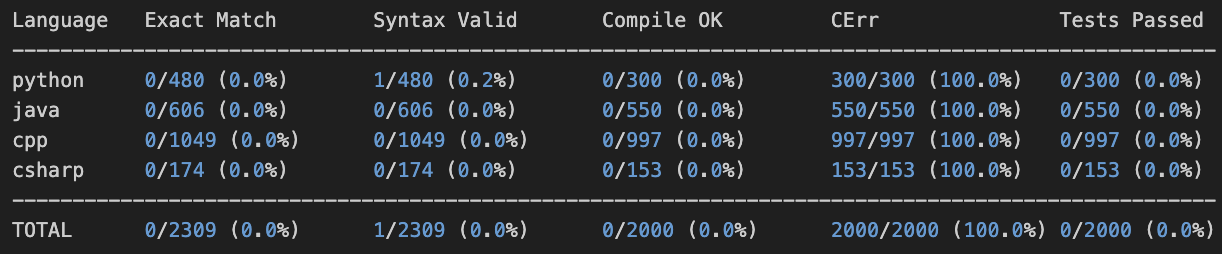
Here is a simple example completion from Qwen-8B:
<|fim_prefix|>
def hello_world():
"""Print Hello World"""
<|fim_suffix|>
hello_world()
<|fim_middle|>\n\nOkay, I need to write a Python function called hello_world that prints \"Hello World\". Let me think. The function is supposed to be defined with def hello_world(): and then inside the function, there's a print statement. Wait, the example code shows the ...
It goes into thinking mode, etc. which is not what we want anyway. Most post-trained models today will be more geared towards agentic coding and so, this is expected.
My Qwen-8B LoRA
Finally, these are my results finetuning the base model on 10M tokens:
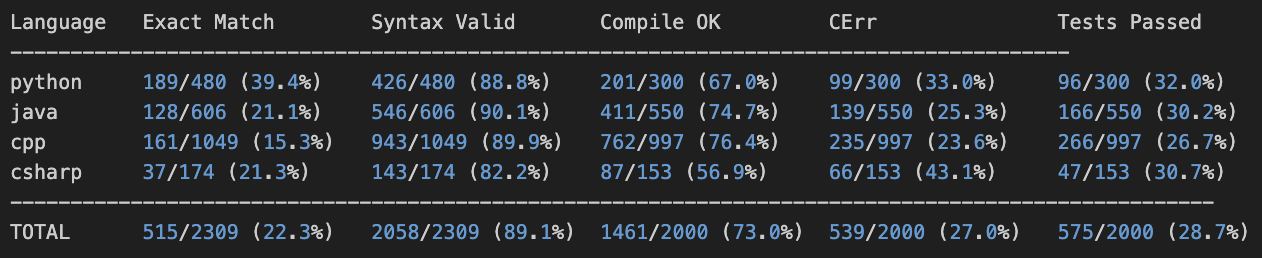
Here is a simple example completion from Qwen-8B-Base-Lora:
<|fim_prefix|>
def hello_world():
"""Print Hello World"""
<|fim_suffix|>
hello_world()
<|fim_middle|> print("Hello World")
Successful!
I spent $10 on this whole experiment (running my finetune job on 10M tokens + other smaller experiments).
Improvements for Tinker
Overall, I really liked the experience. Here are some improvements I would like to see:
- WandB logging support: I wanted to log granular details like entropy, etc. (similar to TRL) to understand the run better. Searching "WandB" in the docs did not lead to any solutions... but after this experiment was done, I found an example in their github cookbook! Mentioning this in the docs would be great.
- More ways of PEFT'ing: I initially wanted to finetune with DoRA, though there currently is no happy path solution for it even with other providers.
- Support for custom models: I want to upload my own model and run SFT on that. I understand that the system is highly optimized for LoRA + supported models, it would be awesome to upload custom models (safetensor compatible) though :)
What's next?
While I have a simple setup, I plan to adopt best practices from their cookbooks to improve my larger run's setup.
As an aside, I love Tinker's business model. They have highly-skilled domain experts building the best system that is more performant, fasted time-to-market and cheaper than a self-managed setup. With their focus on RL, this is further exacerbated as setting up performant RL systems (like PipelineRL) is technical and takes time to get right, Tinker lets you be scrappy and still get SOTA. As long as they can bring in demand to have minimum GPUs idling, they will make a lot of money. I suspect there is lots of GPU liquidity being used so they can spin up and down to fill demand (they made a key hire from Modal too).