So, why is attention quadratic?
We hear about attention being unscalable because it's scales quadratically. When I was a beginner in ML, I used to wonder what this was all about.
What is quadratic about it? why? This simple explanation is catered towards non-AI technical folks with some lin alg knowledge. Also, I am assuming this is plain attention (no multi-heads), batch=1 and no kv caching (btw rumor is anthropic did not have kv caching in it's early days) for simplicity of explanation.
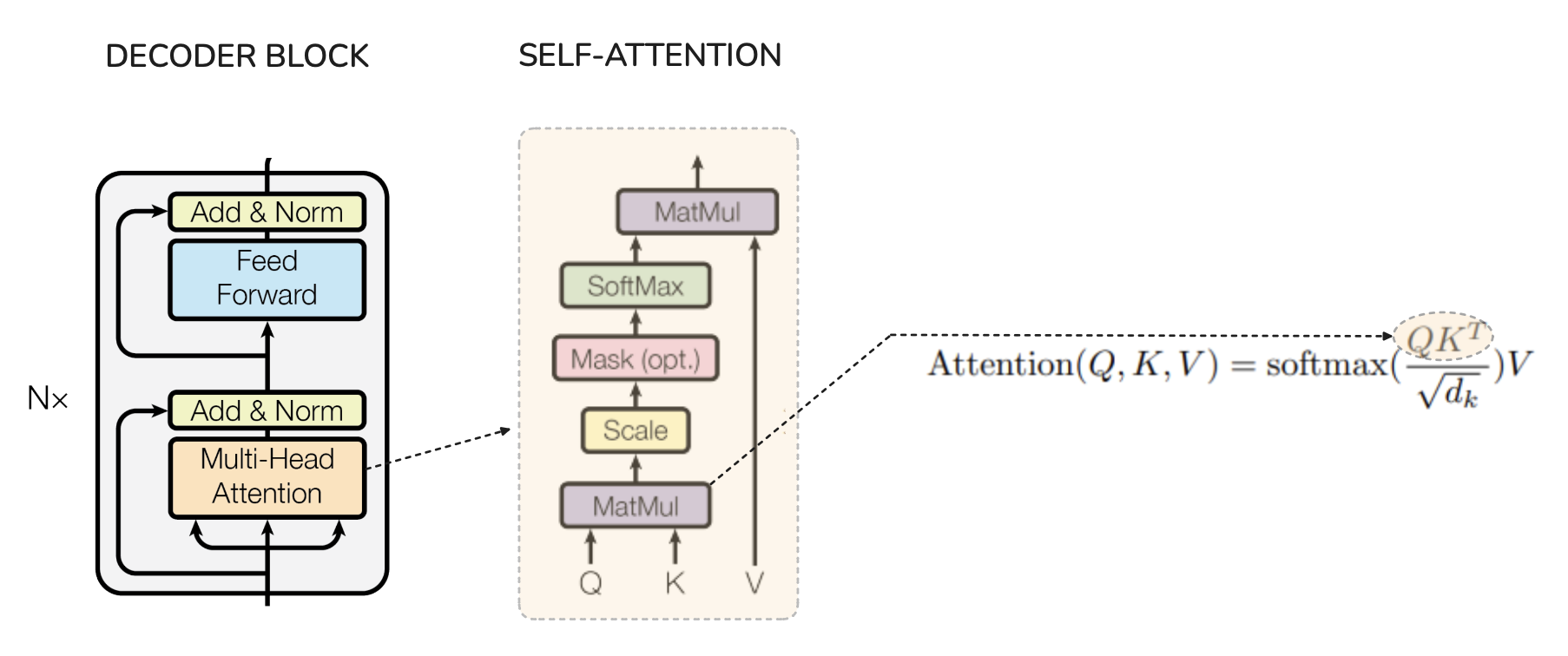
The diagram above shows where attention happens in the decoder block & the formula for attention. Look at the Q @ Kᵀ part of the formula above. Q, K and V are of shape (Sequence_length, Hidden_dim), when Q and K transpose are matmul'd they result in a matrix of shape (Sequence_length, Sequence_length).
During inference, while the sequence increases by 1 for each token, both time to compute and memory to store the result is O(L²). So, when
- sequence length = 1,
Q @ Kᵀ= (1, 1) = 1 multiply - sequence length = 2,
Q @ Kᵀ= (2, 2) = 4 multiplies - sequence length = 3,
Q @ Kᵀ= (3, 3) = 9 multiplies - ... like in the diagram
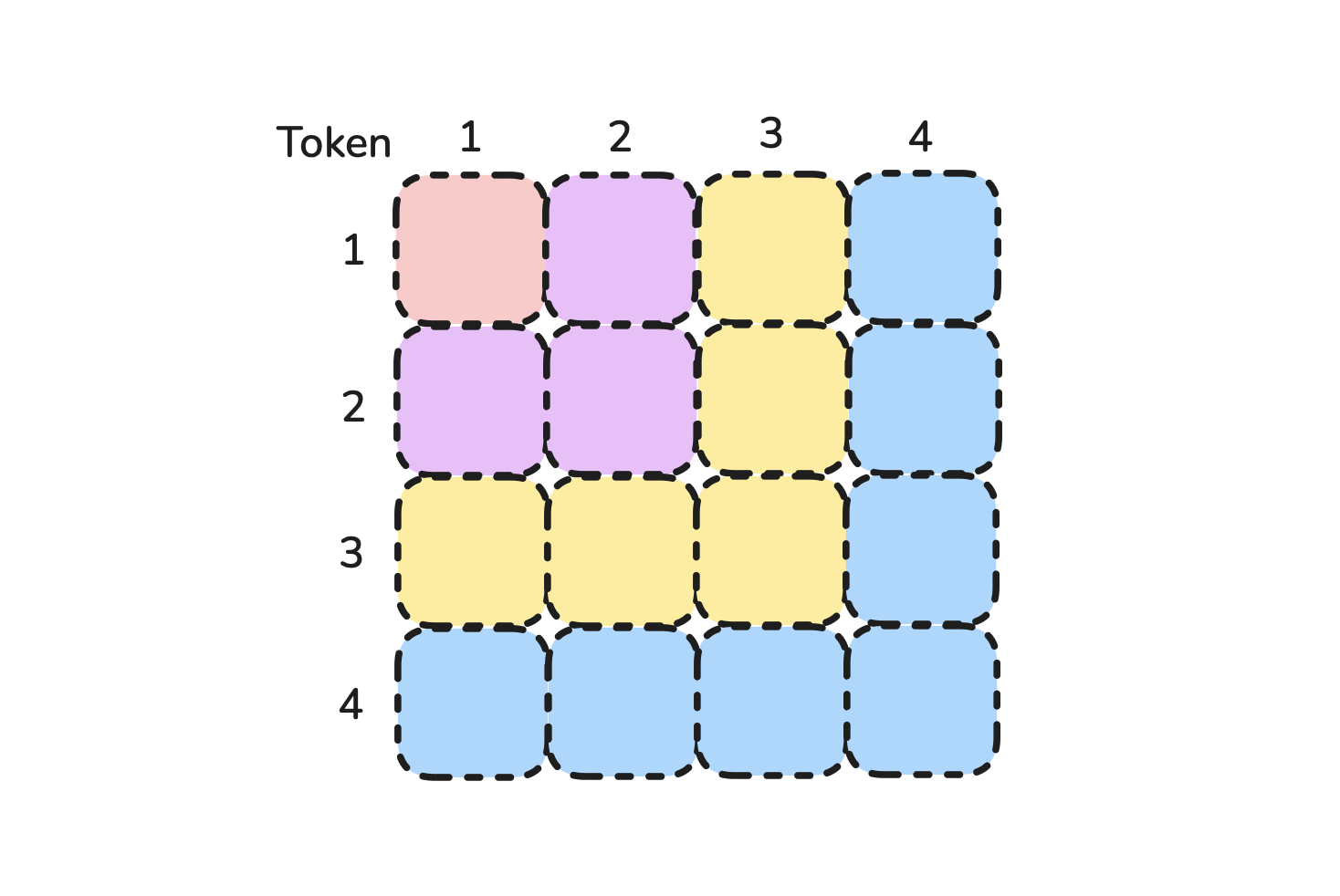
Hope this makes everything clear.
By Omkaar Kamath