Floating Point math
I wanted to write about different floating point formats. I am omitting float64, MXFP6, MXFP4 and NVFP4 for this post.
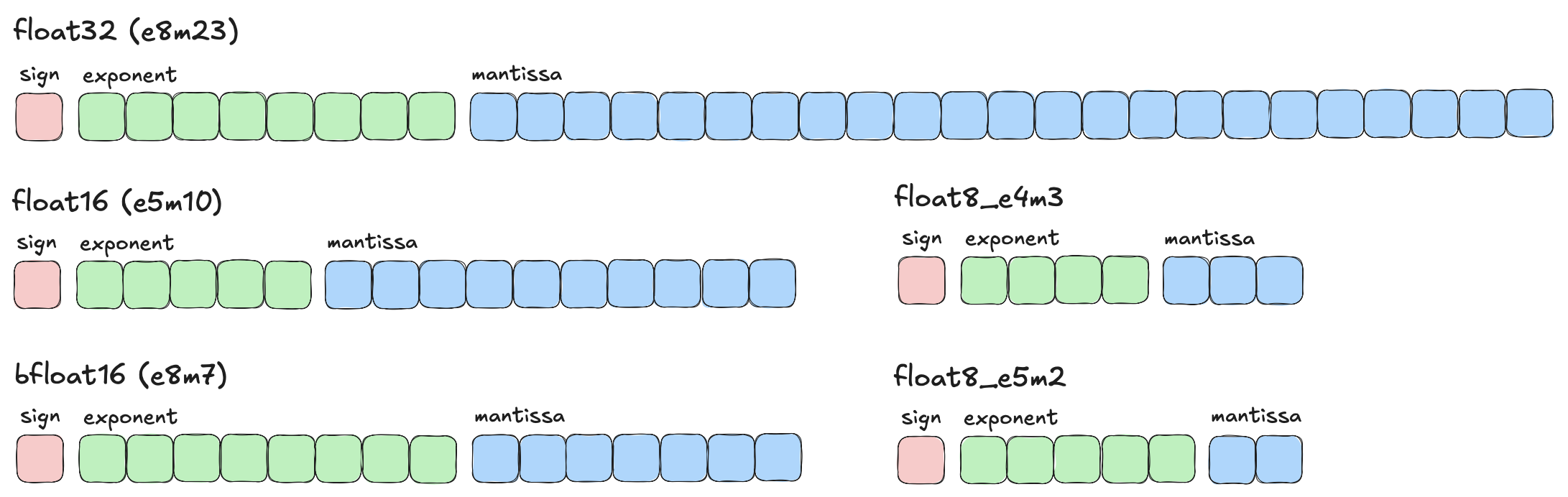
What do mantissa and exponent bits represent?
The sign bit is as in int, 1 is negative and 0 is positive.
Exponents represents an offset binary number. To calculate the real exponent, calculate exponent - bias. The bias value is 127 for f32/bf16 and 15 for f16.
Mantissa represents the fractional part in binary notation with an implicit leading 1 (add 1 to result). Each mantissa bit represents a negative power of 2, so:
1st bit: 2^-1 = 0.5
2nd bit: 2^-2 = 0.25
3rd bit: 2^-3 = 0.125
...
Now, say 10000000 is our 8-bit mantissa, it translates to 1 + 0.5 = 1.5 in base10.
Explore further with the calculator below.
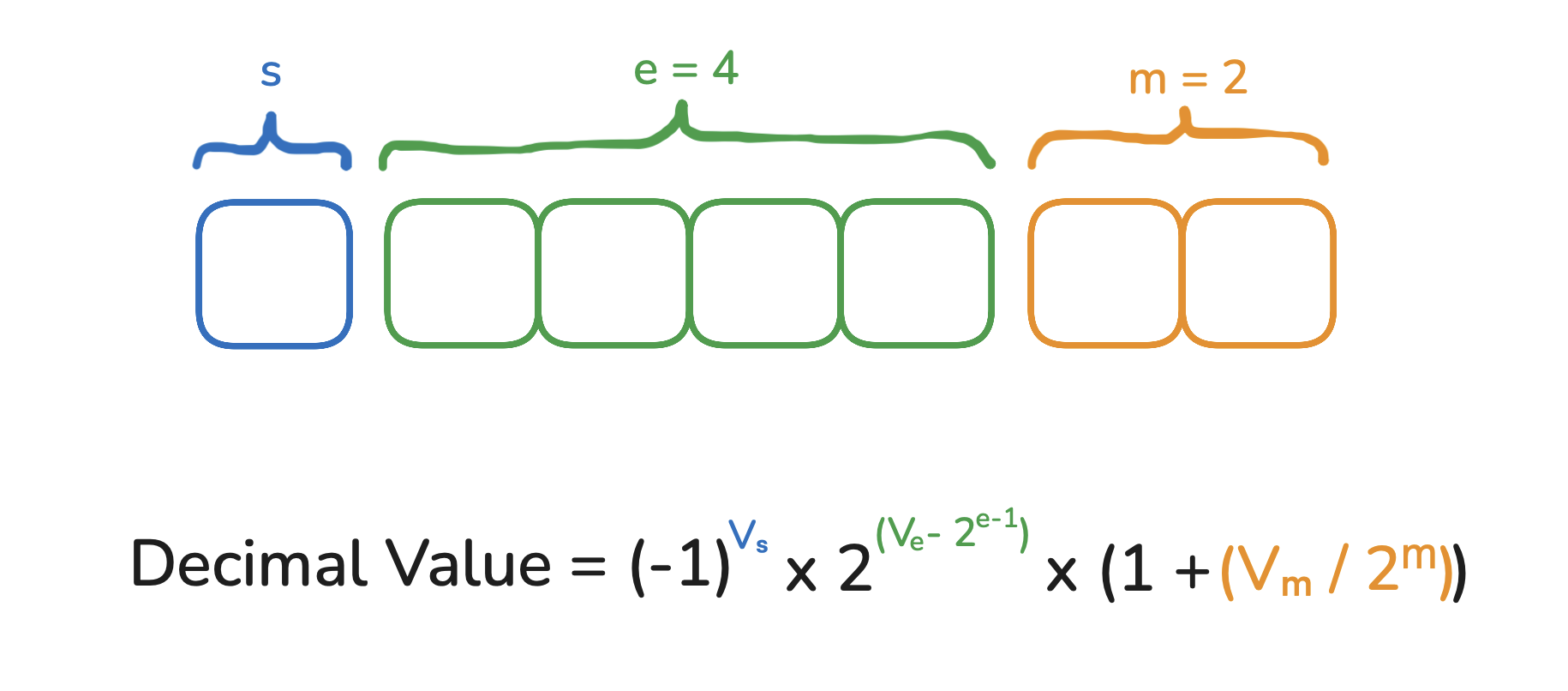
In general, for any floating point number (fp32, fp8, fp4, etc), with 1 sign bit, e exponent bits and m mantissa bits, this is the general formula to calculate it's value. Personally, this really helped me understand fp representation.
Float32
This was the default format for ML. Great support across hardware vendors. f32 has about 7 digits of precision, anything beyond that is usually wrong. The only problem is it's memory intensive, do we really need 8 exponent and 23 mantissa bits?
Float16
Turns out, no! Float16 hardware support is good but turns out cutting down exponent bits really hurt algorithmic performance of ML models. f16 has about 3 digits of precision.
Bfloat16
Enter BF16, with the same 8 exponent bits as float 32 with only 7 mantissa bits. Most new models released on huggingface are now primarily bf16. Hardware + Software support for bf16 is great, making it an instant industry standard. bf16 has about 3 digits of precision too. I'll quote google to explain why bf16 is preferred.
Based on our years of experience training and deploying a wide variety of neural networks across Google’s products and services, we knew when we designed Cloud TPUs that neural networks are far more sensitive to the size of the exponent than that of the mantissa. To ensure identical behavior for underflows, overflows, and NaNs, bfloat16 has the same exponent size as FP32. However, bfloat16 handles denormals differently from FP32: it flushes them to zero. Unlike FP16, which typically requires special handling via techniques such as loss scaling [Mic 17], BF16 comes close to being a drop-in replacement for FP32 when training and running deep neural networks.
Float8
fp8 is getting more common for inference, flash-attention-3 already has an fp8 implementation.
Get mathing
Checkout these calculators to add and multiply on float16 values.
My goal was to write a small blog and cover surface-level details for now. To learn more, I recommend reading this blog by the incredible Julia Evans.
By Omkaar Kamath